06-你的 AI 每天都在失憶——所以 build 產品的第一步,是寫一份文件


在上一個章節後,我們應該已經可以透過跟 AI 對談,誠實地面對自己的問題並討論出一個解決方案。接下來的章節會圍繞在如何快速打造出解決方案,並將其推向市場進行實驗。
由於我們的整個系列都圍繞著 AI 對話,但其實目前的 AI 有個很大的問題。
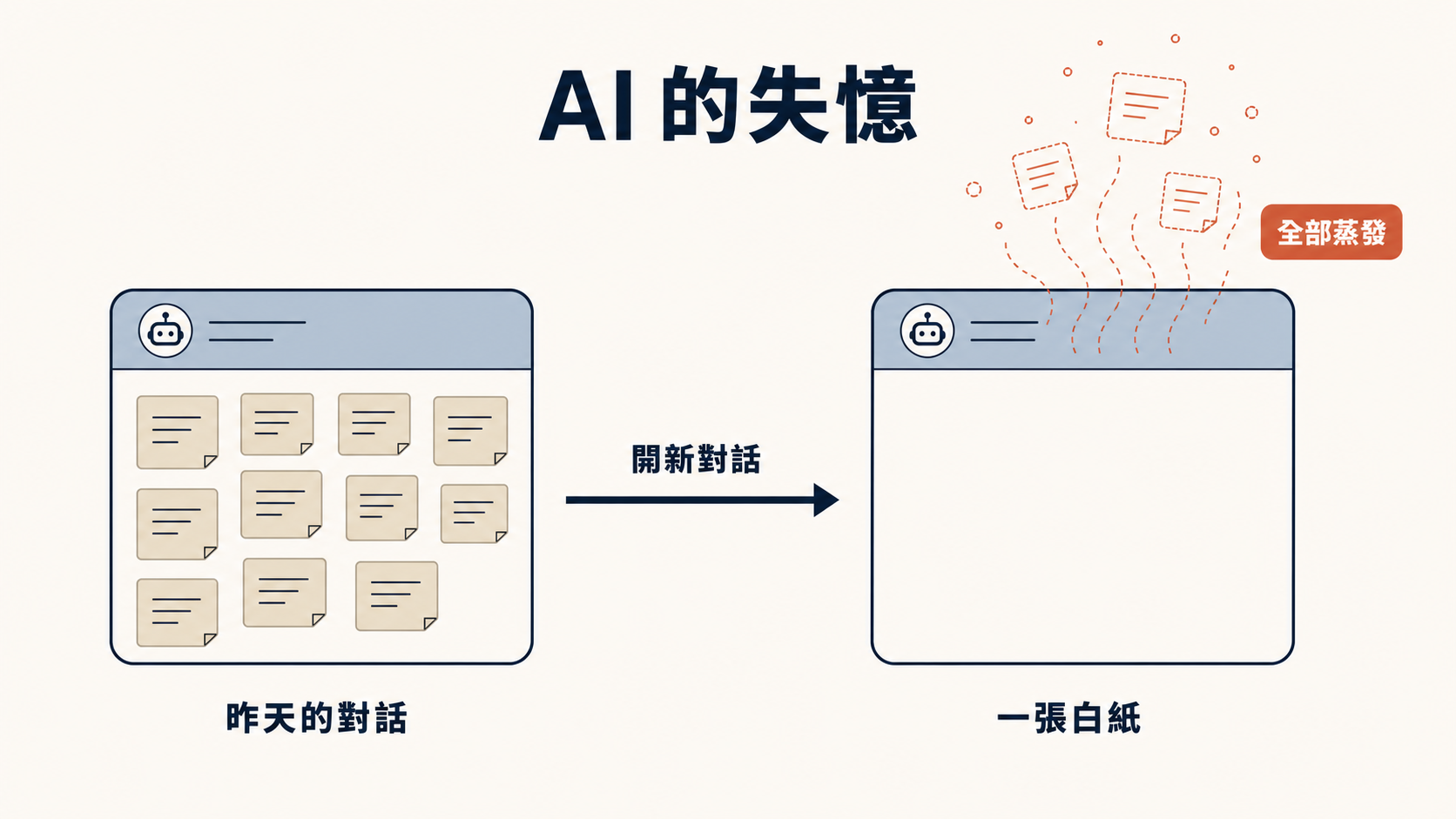
就像我們上一次對話,其實跟 AI 一來一回聊了一整晚,把每一個需求和想法都討論得清清楚楚;但今天你開了一個新的對話想接著做,它就什麼都不記得了。這也是目前主流 AI(像是 ChatGPT、Claude 等)的共同問題:它們的對話缺乏「記憶的傳承性」。
你昨天那些決定、那些「不要這樣、要那樣」的眉角,全部蒸發。
這不是 bug,是 AI 的本質:每一個新對話,它都是一張白紙。
所以正式開始 build 產品的第一步,不是寫 code,是寫文件。
為什麼是文件?因為它是唯一「跨對話還活著」的東西
你可能會想,那我把對話記錄留著不就好了?
問題是,對話記錄是「過程」,不是「結論」。你跟 AI 聊了三個小時,中間繞了多少遠路、推翻了多少想法、講了多少句「啊不對,我剛剛講錯」——這些全部混在一起。等你下次要接手,光是重讀就要半小時,而且新開的那個 AI 根本讀不進去、也不會自己去讀。
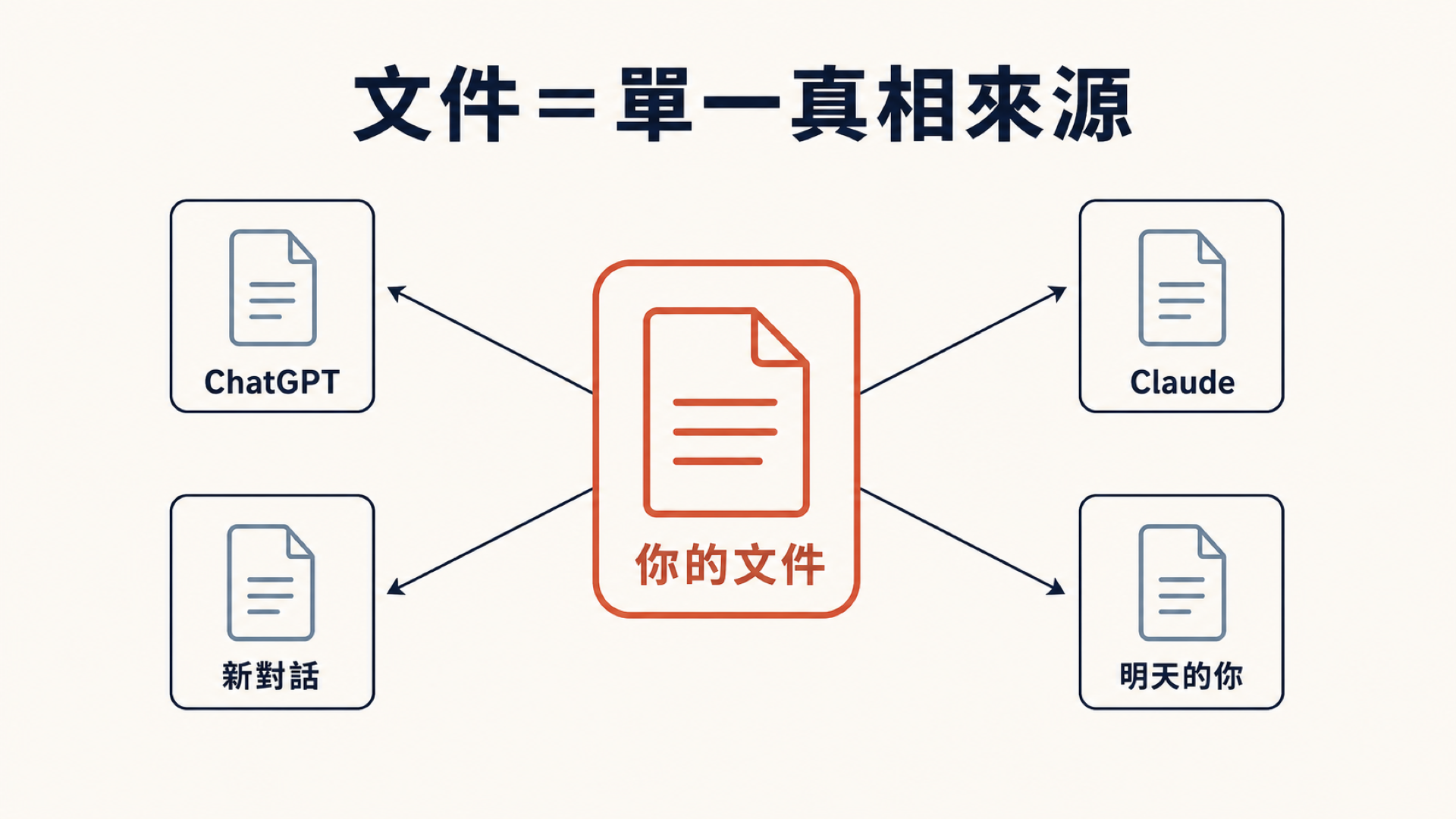
文件不一樣。文件是你把那三個小時裡「真正有價值的結論」濾出來、沉澱下來的東西。它是唯一能跨越一個又一個對話、還一直活著的載體。用一個大家最近很常聽到的說法,它就是你這個產品的單一真相來源(Single Source of Truth,簡稱 SSOT)——任何人、任何一個新的 AI 對話,只要讀這一份,就知道現在的共識是什麼。
我在上一篇文章〈一人公司還剩下什麼〉裡,講過一個我很在意的概念:
能夠自行建立「完整脈絡文件」的公司,將在 AI 時代放大十倍、甚至百倍的產能。
文件就是這麼重要。它不是那種「做完專案才補的交差作業」,它是你整個產品的地基。你把想法、把每一個決定、把來龍去脈都寫成文件,接下來不管換哪一個對話、甚至換哪一個模型,它們都能一讀就接手,站在你昨天的結論上繼續往前,而不是每次都從零開始重新認識你。
可是「文件化」不是叫你先去寫一堆 Word
先講清楚,我不是要你打開 Word、正襟危坐地寫一份幾十頁的規格書。那太重了,你會寫到一半就放棄。
我們有一個比較簡單的方法:直接跟 AI 對話完之後,跟它說一句「幫我把剛剛的討論沉澱成一份文件」。它就會幫你整理出來。這是最低成本的起手式,先做到這一步,都已經贏過大部分「聊完就關掉」的人了。
但這裡有一個陷阱。
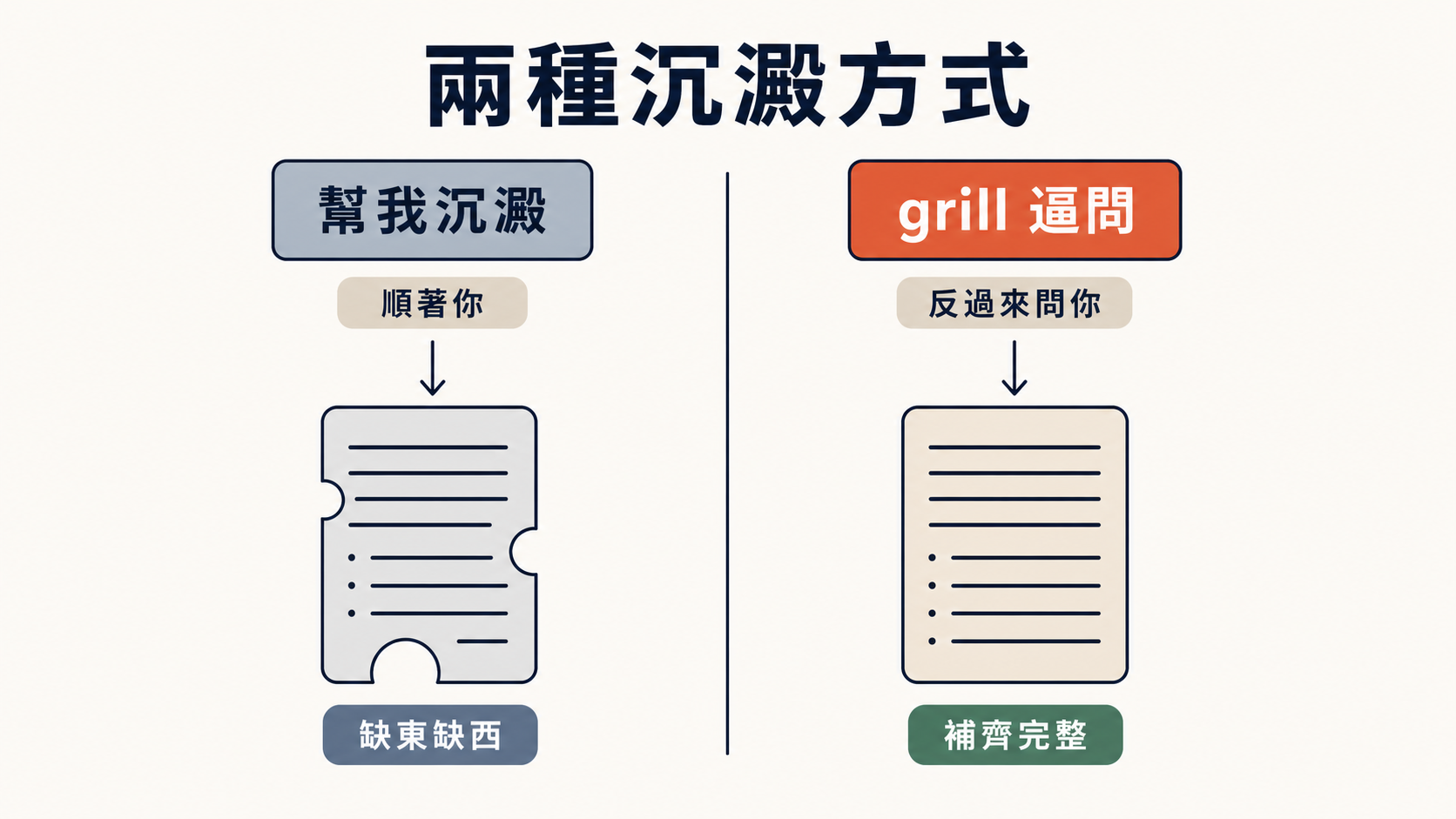
很多時候,我們在對話中,其實沒辦法把所有細節都講清楚。有很多眉角我們自己根本沒想到,而 AI 呢,它只是順著你的想法往下接——你沒問到的,它也不會主動戳你。這就導致你叫它「沉澱成文件」的時候,沉澱出來的東西往往缺東缺西,看起來像模像樣,其實根本稱不上是一份真正的單一真相來源。
此外,這還會產生另一個更隱形的問題:你腦袋裡想的,跟 AI 理解的,其實是不一樣的。你以為你們有共識,文件寫出來你也懶得逐字檢查,等到真的開始 build,才發現它做出來的完全不是你要的東西。大腦跟 AI 的認知,從一開始就沒有對齊。
通常文件會用 Markdown 這個格式,他是一種類似純文字但加上一些簡單的語法如 # 來表示大標題,非常適合 AI 撰寫
所以我這邊會推薦你裝一個技能。你可以直接跟你的 AI(Claude Code、Codex 這類)說:
幫我安裝這個技能到全域:https://github.com/mattpocock/skills
這是一位叫 Matt Pocock 的工程師(前 Vercel 工程師,做過很多前端圈的知名教學)公開出來的一整套技能,短短時間就衝到十幾萬顆星。他自己的標語很直接:這是「給真工程師用的技能,直接從我自己的 .claude 資料夾拿出來」——不是那種玩票的 vibe coding,是他每天真的在用的東西。
裝完之後,這一整包裡面,我要你先用的那一個,叫做 grill-with-docs。
grill 這個字,是「拷問、逼問」的意思。這個技能做的事情,跟前面那個「幫我沉澱成文件」剛好相反——它不順著你。它會像一個很資深、很機車的前輩坐在你對面,一次只問你一題,抓住你每一個含糊的字眼往死裡問,逼到你把每一個決定都講清楚為止。而且,它會在逼問的過程中,一邊把你確定下來的決定,即時寫進文件裡。
你發現這解決了什麼問題嗎?
它解決的正是「AI 只會順著你、文件缺東缺西」這件事。因為它的工作不是討好你,是挑戰你——把你自己都還沒想清楚、卻以為想清楚了的那些洞,一個一個戳出來。有人在網路上形容得很好:裝了它之後,Claude 才真的像個資深工程師,而不是一個只會說「好的沒問題」的應聲蟲。
從一句模糊的想法,到一份能開工的文件
光講你可能沒感覺,我直接示範一次給你看。
今天就用一個簡單的小 App 來做範例吧,「我想做一個提醒爸媽吃藥的 App。」
如果我照最偷懶的做法,直接叫 AI 幫我把這句話變成文件、然後開始寫 code,我大概會做出一個很普通、市面上一抓一大把的服藥提醒 App,然後上線之後沒人用。
但我這次先做了一件事:在桌面開一個資料夾,把這個念頭、還有等一下所有討論出來的東西,全部丟進去(沒錯,就是你正在讀的這篇文章,我自己也是這樣做的)。然後我打開裝好 grill-with-docs 的 AI,把那句話丟給它,讓它開始拷問我。
接下來這段,是我把那場拷問濃縮下來的樣子。你注意看,每一輪它問完,我的答案是怎麼變的:
它問: 誰在用這個 App?爸媽自己按提醒,還是你在看?
我: 呃……都要吧。
它逼: 「都要」代表你還沒決定誰是真正的使用者。只能先做好一邊,你選誰?
我: 子女。真正會焦慮的是我們,我爸媽根本不覺得這是問題。
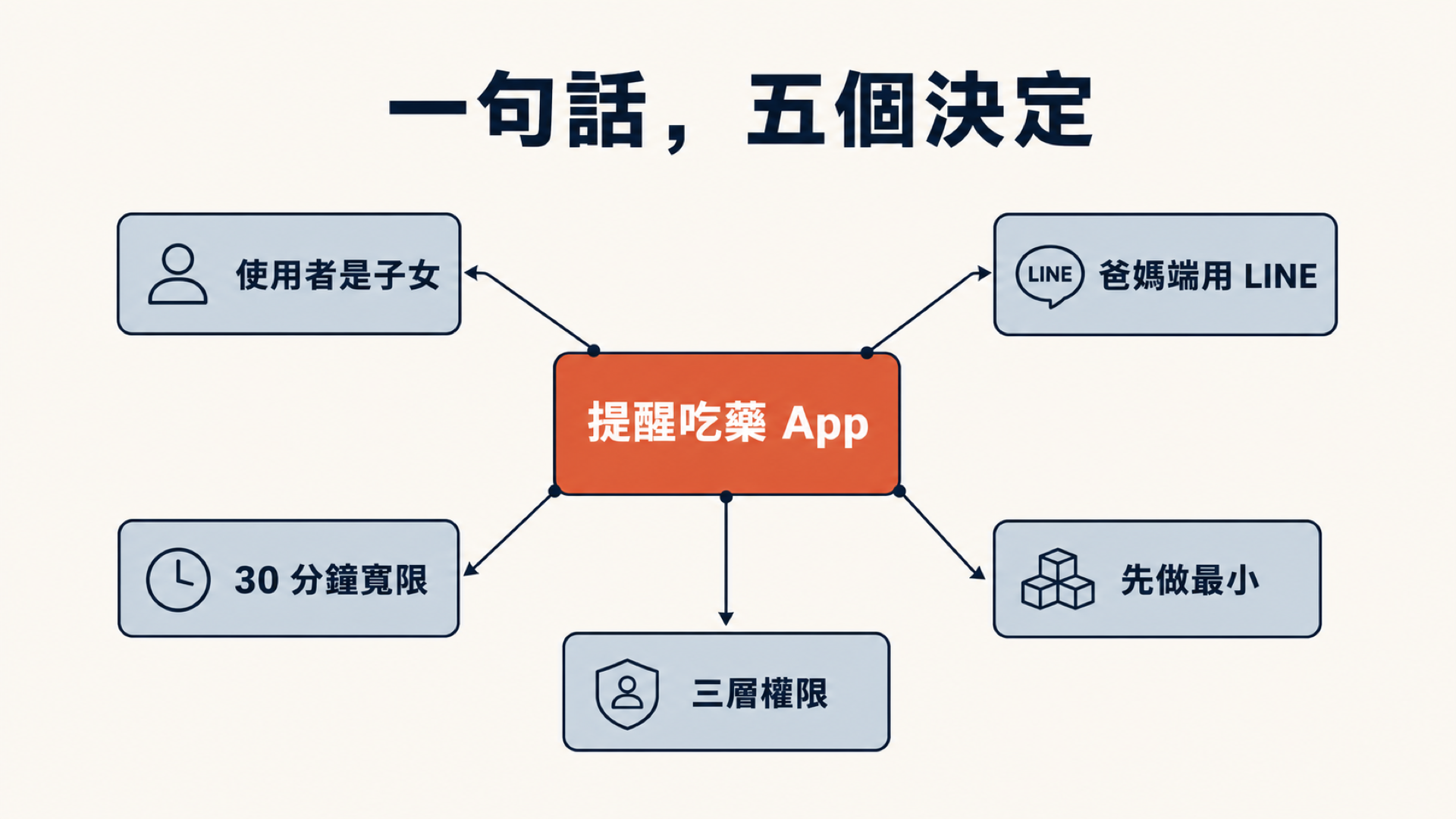
第一個決定,兩分鐘內就冒出來了:主要使用者不是爸媽,是子女。 這一刀下去,整個產品的設計方向就變了。
它問: 那爸媽那端呢?如果他們根本不太會用手機?
我: ……教他們裝一個新 App,根本不會有人做。
它問: 他們現在用什麼?
我: LINE。天天在傳長輩圖。
它: 答案已經在你手上了——爸媽端不裝新 App,走 LINE 推播,一個按鈕回報「吃了」。
第二個決定:別教用戶用新工具,用他們早就會用的工具。
它問: 沒按怎麼辦?
我: 通知我吧。
它問: 立刻通知,還是等一下?
我: 立刻會很煩,我媽可能只是去洗澡。
它: 所以你在意的不是「有沒有立刻按」,是「有沒有真的吃到」。要留緩衝——多久合理?
我: 30 分鐘。
第三個決定:30 分鐘寬限期,才升級通知——把「即時警報」換成「真正該關心時才吵你」。
它問: 一天吃幾種藥?幾次?
我: 我媽血壓藥、血糖藥都有,早晚各一次。
它: 你要 MVP 就處理掉所有藥物、複雜排程,還是先砍到最小?現在全做,你可能三個月都上不了線。
我: ……先做最小的。單一長輩、單一時段,先把核心迴圈跑通。
第四個決定:第一版鎖死在最小可行的範圍,其餘留到以後。
它問: 這是健康資料。誰能看到「爸媽有沒有吃藥」?
我: ……我沒想過這個。
它: 分三層講。什麼絕對不能做?
我: 不能把紀錄分享出去,也不能給任何「該不該吃這個藥」的醫療建議。
它: 什麼要先問過你?
我: 以後想加其他家人進來看,要先問過我。
它: 什麼可以直接做、不用每次確認?
我: 加密儲存、固定時間發提醒——這些該預設就能跑。
第五個決定:把權限切成三層——永遠不做的、要先問過的、可以直接做的。
你發現了嗎?十分鐘前,我以為這只是「做一個提醒 App」,一句話的事。十分鐘後,我手上多了五個決定——而且每一個,要是我沒先講清楚就動手寫 code,都得推倒重來。
這五個決定,就是我接下來要寫進正式文件的東西。這時候,我再叫 AI 幫我把整場對話收斂成一份 PRD(Product Requirements Document,產品需求文件)——它會照一個固定的結構,把「要解決什麼問題、給誰用、要做哪些功能、哪些先不做」全部條列清楚。
到這一步,我才算真的「準備好開始 build 了」。而且從今以後,不管我哪天換一個新對話、換一個新模型,我只要先把這份 PRD 丟給它,它就瞬間補齊了我這十分鐘拷問出來的所有共識——不用再從那句模糊的話重新開始。
那一份「好」的文件,長什麼樣子?
你可能會問:那我怎麼知道文件寫得夠不夠好?
我的判斷標準很簡單——一份好的文件,要能讓一個「完全沒參與過討論的人」(不管是新來的夥伴,還是一個全新的 AI 對話)讀完就知道怎麼動手,而且不會做出你不想要的事。
要做到這件事,有幾個區塊我建議你一定要寫進去:你希望它遵守的規則與慣例、你的專案結構長怎樣、你偏好的做事風格(最好直接給範例,別只用形容詞),還有最重要的——邊界,也就是「它不准做什麼」。
這個「邊界」,我自己習慣切成三層,剛好對應到剛剛「呷藥了沒」逼出來的那第五個決定:
- 🚫 永遠不做:踩到就是災難的紅線,直接寫死。像是「絕不把用藥紀錄分享出去」「絕不給醫療建議」。
- ⚠️ 要先問過我:有風險、但不是絕對禁止的動作,做之前一定要停下來問你一句。像是「要擴大誰能看到紀錄」。
- ✅ 可以直接做:核心功能,預設就放手讓它跑,不用每次都來煩你。像是「加密儲存、固定時間發提醒」。
這三層,其實就是你跟 AI 之間的信任契約。你把邊界寫得越清楚,你就越敢放手讓它自己跑——因為你知道,就算它自己跑,也不會跑出你劃的線外面。

最重要的一件事:文件是活的,要一直養
到這裡,你可能以為文件寫完就沒事了。剛好相反——這才是最多人做錯的地方。
大部分人把文件當成「寫完封存」的東西:開工前寫一份、然後就再也不打開。但你的產品是會長大的:你會做新的決定、會推翻舊的想法、會發明新的詞彙。如果文件停在第一天,那它很快就會跟現實脫節,變成一份「看起來是真相、其實早就過期」的東西——那比沒有文件還危險,因為 AI 會很認真地照著一份錯的文件幫你做錯事。
所以你要把文件當成一個要一直養的東西。每次你做了一個新決定,就回頭把它補進去;每次某個講法變了,就回去更新。讓這份文件永遠反映「此時此刻的最新共識」。
我自己在做這件事的時候,還會多做一個小動作:給重要的段落標上「最後確認日期」。如果一段東西放了很久都沒有人回來看、沒有人確認它還算不算數,我就會把它降級——因為在一個變化這麼快的專案裡,一段沒人維護的舊資訊,很可能已經是錯的了。
這也是為什麼,我整個工作系統——從專案的入口文件、到每一個小技能、到每天的工作紀錄——都不是寫一次就丟著,而是每天都在被我一點一點地補、一點一點地改。文件不是我工作的產物,文件就是我工作本身。
收尾:把瓶頸從你的腦袋,搬到一份文件裡
寫 code 這件事,在 AI 時代已經快到不像話了。真正的瓶頸從來不是「打字速度」,而是「你到底有沒有想清楚要 build 什麼」。
而「想清楚」這件事最麻煩的地方在於:它發生在你腦袋裡,而你的腦袋會忘、會亂、會自我欺騙,更慘的是——你沒辦法把腦袋直接接到 AI 上。
文件化,就是把這個瓶頸,從你那顆會失憶的腦袋,搬到一份可以被一讀再讀、可以跨越每一個對話、可以交給任何一個模型的源頭裡。這就是你在上一篇文章看到的那句話——把自己變成一個 AI 讀得懂、能自己跑的源頭——落地的第一塊磚。
先別急著寫 code。先開一個資料夾,讓 AI 好好拷問你一輪,把那五個、十個你自己都還沒想清楚的決定逼出來,寫成一份文件。
這一步做紮實了,後面的 build,才會快得起來。
下一篇,我們就拿著這份 PRD,真的把「呷藥了沒」做出來。到時候你會發現,因為前面文件寫得夠清楚,寫 code 的過程反而是整件事裡面最輕鬆的一段。
做好了,或者你正在路上,都歡迎來我的 Threads 跟我聊聊,你的第一份 PRD 逼出了幾個你原本沒想到的決定。