Harness Engineering:做 AI 產品工程師必須得知道的新技能

你大概也遇過這種情況:同樣是用 GPT-5.5 或 Claude Opus 4.7——X 上看到別人的 demo 跑得超順、agent 連續工作幾小時都不會崩;到你自己手上,它做幾步就跑偏、把你叫它做的事誤解、或自信地說「修好了」但實際根本沒跑通。
第一反應通常是:是不是 prompt 沒寫好?是不是 RAG 沒調明白?是不是模型不夠強?
都不是。
差距在一個你可能從沒聽過、但 2026 年最頂尖的 AI 團隊正在投入最多人力的東西——Harness Engineering。
這篇我寫給「做 AI 產品落地的工程師」——不是訓練模型的研究者,是把 AI 用在實際業務上、做 Agent 的人。我會講清楚:Harness Engineering 是什麼、為什麼這個詞現在才出現、5 個維度該怎麼設計、業界頂尖團隊(Anthropic / OpenAI)怎麼做、以及你今天就能動手調的 3 件事。讓我們開始吧。
1. 你不是 AI 工程師,你是用 AI 的工程師
先把受眾切清楚。
過去兩年,「AI 工程師」這個詞被很多人混用。但其實做這件事的人分兩種:
| 類型 | 你的工作 | 你關心什麼 |
|---|---|---|
| AI 研究 / 模型工程師 | 訓練模型、調參數、做 fine-tuning、寫 paper | 模型本身的能力 |
| AI 應用工程師(這篇給你看的) | 把現有模型(Claude / GPT / Gemini)裝進真實產品、做 Agent、做 RAG、做工具串接 | 模型在你產品裡能不能穩定跑 |
這兩個族群解的問題完全不同。
AI 應用工程師的痛點是這樣:你的模型本身已經夠強了——GPT-5.5、Opus 4.7、Gemini 3 Pro 任一個丟到你產品裡,單次回答都漂亮。但只要你把它接成連續任務的 Agent,它就會:
- 計畫做得很完美、執行時跑偏
- 誤解了 API 回傳的資料
- 一步做錯後續全錯、而系統毫無察覺
- 對話越長越笨、最後忘掉前面定的規則
- 自信地說「完成」但實際沒跑通
問題不在模型強不強,問題在你能不能控制它。
這個「控制」的工程,就叫 Harness Engineering。
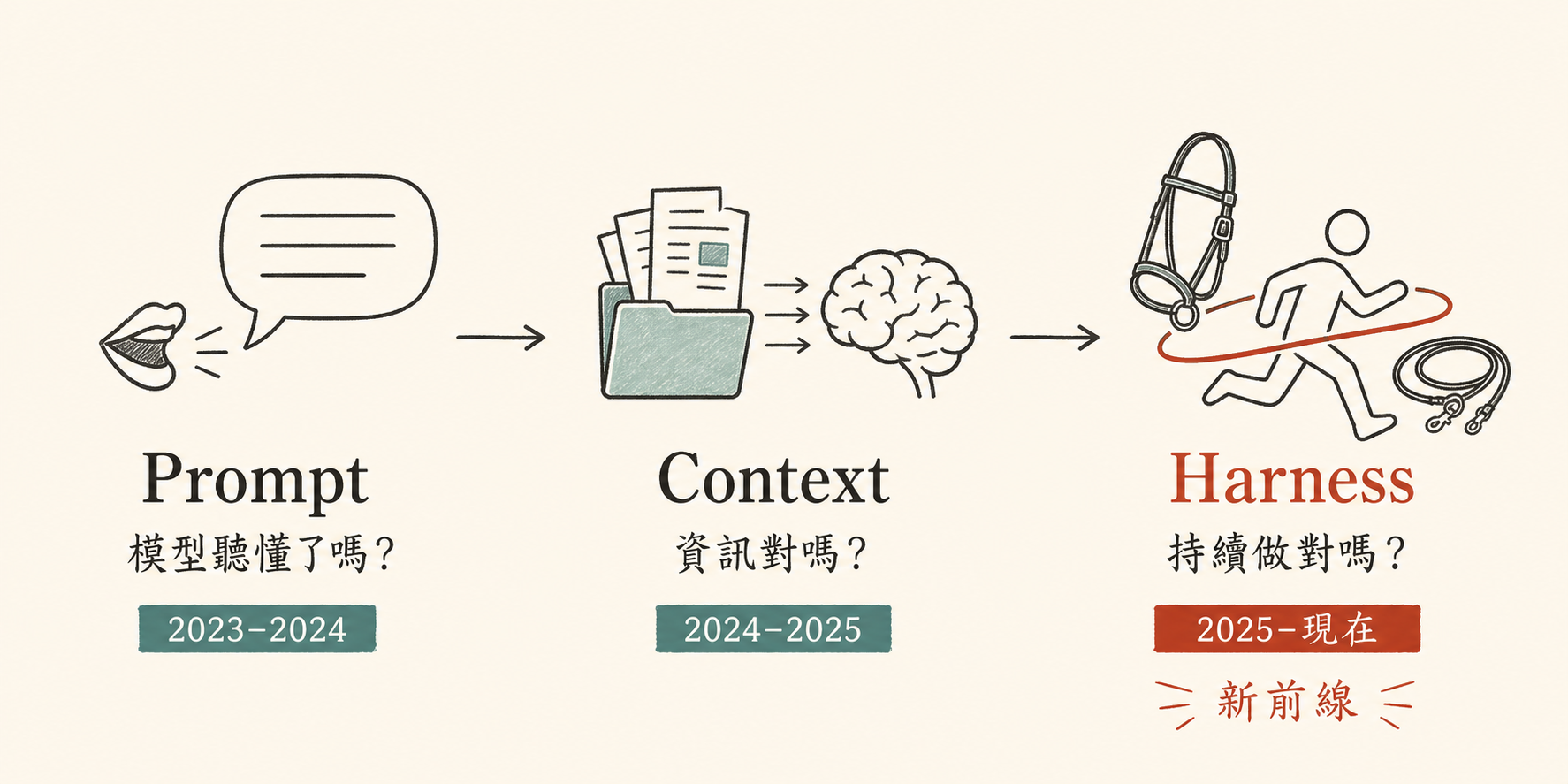
2. AI 工程的三階段演進——你現在卡在哪一階?
過去兩年,AI 工程的重心經歷了三次明顯的轉移。每一階對應一個你會踩到的痛點:
Prompt Engineering Context Engineering Harness Engineering
「模型聽懂了嗎?」 → 「模型拿到對的資訊嗎?」 → 「模型在執行中能不能持續做對?」
第一階段:Prompt Engineering(2023–2024)
最早的痛點:你問同一個問題、換個說法,輸出品質差一個量級。
「幫我總結這篇文章」vs「請以資深技術編輯身份,用三段式總結這篇文章——第一段觀點、第二段論證、第三段限制」——後者的輸出質量明顯高一截。
那個階段的共識:模型不是不會做,是你沒把問題說清楚。各種 role play、few-shot、結構化提示應運而生。
這階段的核心能力是語言設計,不是系統設計。
第二階段:Context Engineering(2024–2025)
很快就撞到天花板。
因為當你要 Agent 去分析公司內部文件、抓產品最新狀態、調用外部 API——再漂亮的 prompt 也無法憑空產生事實。
重心轉移到:怎麼把對的資訊、在對的時機、餵給模型。RAG 是這階段的典型,但成熟的 Context Engineering 遠不止「檢索一下」——它涉及:
- 文件怎麼切(chunking)
- 檢索結果怎麼重排(reranking)
- 長文本怎麼壓縮
- 歷史對話怎麼摘要
- 多 Agent 之間傳原文、摘要、還是結構化資料
到了 2025 末,這層也出現新方法叫「漸進式披露」(Progressive Disclosure)——不一次把所有工具說明塞進 context、而是 Agent 明確要用某個工具時才動態載入它的詳細 SOP。
第三階段:Harness Engineering(2025 末–現在)
但你會發現——就算 prompt 完美、context 也到位,在長鏈任務裡 Agent 還是會跑偏。
這就是 Harness Engineering 出現的場景。它關心的不是模型「會不會想」,是模型「會不會持續做對」——包括跑偏時拉回來、出錯時自己修、長任務時不要失憶、有護欄不讓它把 production 燒了。
業界有個公式已成共識:
Agent = Model + Harness
模型是 Agent 的「腦」,Harness 是模型周圍的所有工程結構——記憶、工具、編排、驗證、護欄。
模型是稀少資源(你買 Anthropic / OpenAI 的),Harness 是你的工程能力(沒人能替你做)。
3. 馬具的比喻——為什麼是 Harness 不是別的詞
「Harness」直譯是馬具。
Opus 4.7、GPT-5.5、Gemini 3 Pro 這些旗艦模型,就像三匹頂級烈馬——爆發力強、能跑、有後勁,但沒馬具的話它跑去哪你管不到。
Harness Engineering 就是給這匹烈馬上馬具:
- 韁繩(讓你能拉它的方向)
- 馬鞍(讓你能持續坐在上面)
- 眼罩(避免它被旁邊的東西分心)
- 馬鐙(讓你出力踩住、不會被甩下)
沒馬具:烈馬亂跑、最後翻車。有馬具:烈馬聽你話、跑得遠、跑得穩。
差距不在馬本身——在馬具上。
這也解釋了一個業界觀察:LangChain 工程師做過實驗——完全不動模型權重、只優化 Agent 周圍的工程結構,他們的 coding agent 在 Terminal-Bench 2.0 上從 52.8 分衝到 66.5,排名從 30 名外進前 5。同一匹馬、換馬具,跑出兩個世界。
Enforce quality with mechanisms, not prompts.
業界這條原則已經成共識——靠機制保證品質,別靠 prompt。Prompt 是請求、機制是強制。請求會被忽略、強制不會。
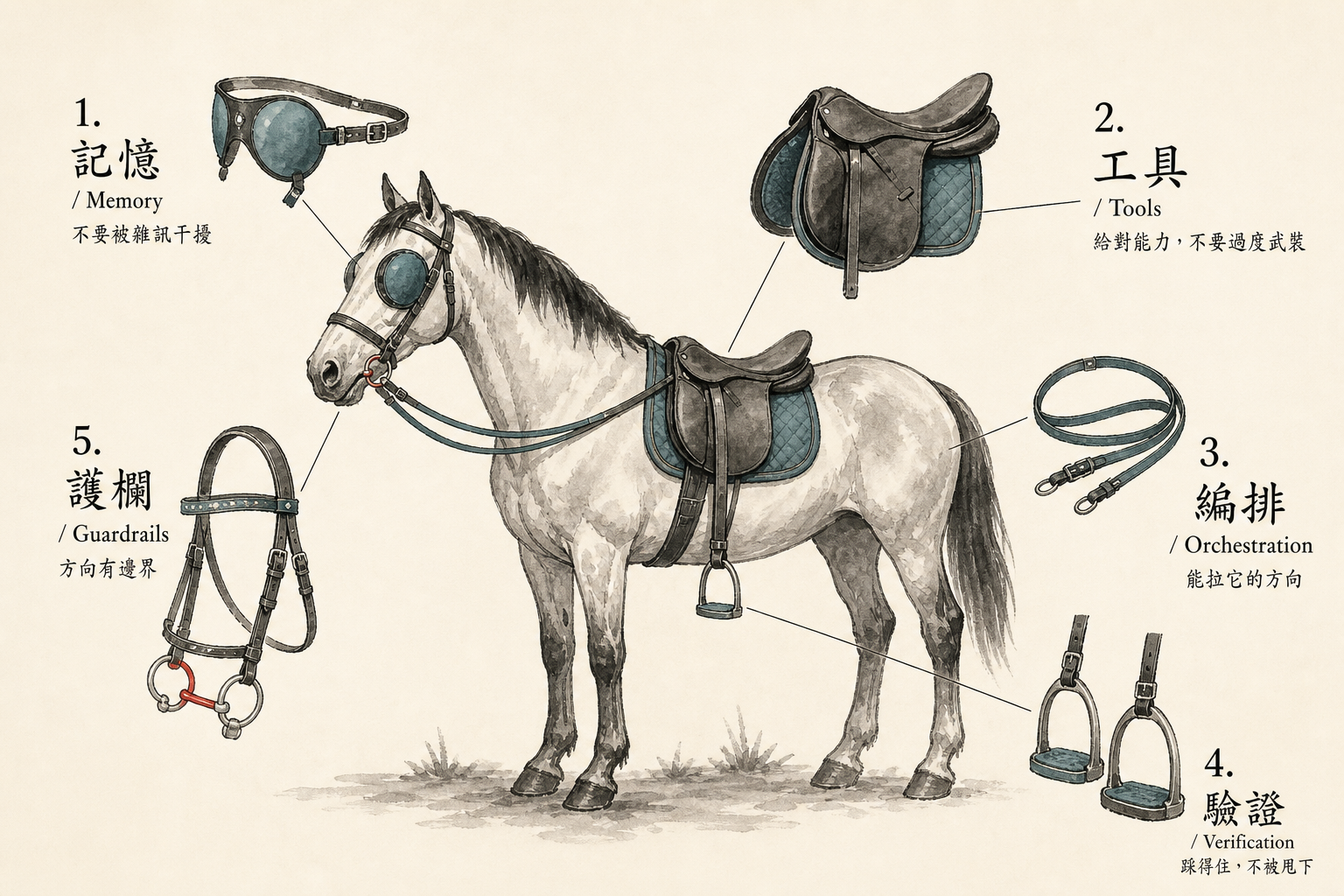
4. Harness 的 5 個維度——你工程的檢查清單
接下來進深水區。
我把成熟的 Harness 拆成 5 個維度。每個維度給你 2-3 個可動手的具體做法。讀完這節你可以拿這 5 個維度回去檢查你自己的 Agent——你在哪幾個維度是裸奔、哪幾個還算到位。
4-1. 記憶(Memory / Context)
問題:模型上下文是扁平的訊息列表——對話越長、前面定的規則越被稀釋、最後它記不住核心約束。
OpenAI 在 Codex 工程文章裡有句話點破:「從 Agent 的角度看,運行時拿不到的知識就等於不存在」。你嘴上說的、Slack 裡討論的、團隊心裡默認的規則——如果沒有以檔案形式存在 repo 裡,AI 看不見。
具體做法:
-
檔案化規則、結構化分層
- 第一層
AGENTS.md(或CLAUDE.md)放在 repo 根目錄,當作專案地圖。100 行內,每次新對話都被自動載入。內容:技術棧、目錄結構、禁止事項、commit 前必跑的指令、UI 風格禁區。 - 第二層
docs/下按主題拆分的詳細文件(frontend.md/api-design.md/security.md)。第一層只列「指引」、Agent 真要做相關任務時再去讀第二層。 - 第三層原始紀錄(git log / 完整日誌)。不自動載入,Agent 用 grep / tail 主動檢索。
- 第一層
-
避開大檔陷阱——OpenAI 自己踩過:最初把所有規則塞進一個幾千行的大
AGENTS.md,結果 AI 反而更容易忽略關鍵資訊。後來改成「地圖 + 詳細文件」兩層才修好。 -
跨對話狀態外置——下面 4-3 編排會講進階版(
progress.md)。
4-2. 工具(Tools / Capabilities)
問題:模型本身只能輸出文字。要它真的做事——跑指令、看結果、調 API——你得接工具。
具體做法:
-
三層工具堆疊
- 基礎:終端 + 檔案系統 + 瀏覽器(讓 AI 能跑指令、讀寫檔、看真實渲染結果)
- 進階:MCP(讓 AI 接外部能力——資料庫、搜尋、爬蟲、設計工具的標準協定)
- 高階:Skills(把多步驟工作流封裝成可呼叫的能力包)
-
工具不是越多越好——這是業界踩過的反直觀坑。Vercel 內部做 text-to-SQL Agent 時最初造了一堆專用工具(schema lookup、query validation、error recovery),成功率 80%。後來砍掉 80% 工具、只讓 Claude 用
grep / cat / find / ls這些 Unix 基礎工具自己讀檔再寫 SQL——成功率衝到 100%、速度快 3.5 倍、token 省 37%。
原因:工具越多、模型每一步的選擇空間越大、選錯路徑的機率也越大。每接一個工具前先問自己「它解決的具體行為缺口是什麼?」——答不上來就先不接。
4-3. 編排(Orchestration / Long Tasks)
問題:模型 one-shot 一個完整 feature 的失敗率超高。讓它一次吃下「帶搜尋、過濾、分頁的列表頁」,等於要一個工程師不寫設計文檔、不拆任務、不分迭代、悶頭幹到底——失敗是必然。
具體做法:
-
Plan Mode——AI 先輸出任務方案(拆成哪幾個子任務、每個怎麼做),人工確認後才動手。把「方向走偏」的成本提前到方案階段消化掉。
-
步進執行 + 狀態外置——每次只做一個子任務、做完一個驗證一個。最關鍵的工具是一份
progress.md:每完成一個 feature 就讓 AI 寫上「當前完成了什麼、用什麼技術方案、有哪些未解的 bug、下一步要做什麼」。這份檔案是跨對話的外置記憶。 -
Ralph Loop(Anthropic 官方)——已進
anthropics/claude-code的plugins/ralph-wiggum。本質是兩段式接力:- Initializer Agent——只在專案最開始跑一次,搭環境、拆 feature list、寫第一份
progress.md、首次 git commit - Coding Agent——每個新對話跑這段:先讀 git log、再讀 progress.md、從未完成列表挑優先級最高的做、做完跑驗證、git commit、更新 progress.md
哪怕中途 AI 斷了、模型版本換了、對話塞滿了——下一輪只要讀 git log + progress.md 就能立刻進入狀態。
progress.md+ git commit 是 AI 的存檔點。 - Initializer Agent——只在專案最開始跑一次,搭環境、拆 feature list、寫第一份
4-4. 驗證(Verification / Feedback)
問題:模型不會跑代碼——它讀代碼字面、根據「看起來像不像能跑通」做判斷。所以它會自信地說「修好了」但其實沒跑。
這條是 Anthropic 反覆強調的 「給 AI 驗證自己工作的方式,是你能做的最高槓桿事」——一個 6 行 config 的 PostToolUse hook 跑 npm test、就能拉一倍可靠性。
具體做法(三層反饋):
- 規則反饋——每次提交前自動跑 linter / typecheck / 單元測試 / 整合測試。任何一項失敗都不算完成。
- 視覺反饋——UI 類任務讓 AI 用 Playwright 自己開瀏覽器、按用戶路徑點一遍、截圖當完成證據。
- LLM 互評——讓另一個 AI 評審第一個 AI 寫的代碼。注意:生成者跟評審者必須分開——Anthropic 經驗:讓生成 AI 評自己會偏向「找理由說自己對」,把它們做成兩個獨立 Agent、用不同角色配置才能真發現問題。
檢查層級(按速度排序):
PostToolUse Hook (毫秒級) ← 最快、最便宜、最頻繁
pre-commit Hook (秒級)
CI 跑 (分鐘級)
人工 review (小時級) ← 最慢、最貴、最少跑
規則:能在快的層攔住的東西、絕不留到慢的層。
4-5. 護欄(Guardrails / Architecture)
問題:AI 寫代碼會模仿 repo 裡已有的模式——好代碼會被模仿,爛代碼也會被模仿。每次單看 AI 的 commit 都合理、疊加起來卻是專案越改越糟。
OpenAI 在 Codex 工程文裡點過這個現象:「Agent 會放大已有的模式」——已有不一致、不穩定、爛的,AI 都會放大。
具體做法:
- 架構規則寫進 linter——不只查語法(typo / unused var)、而是查架構違規。比如「UI 層不能直接呼叫資料層」「模組依賴必須單向」「檔案大小超過 X 行要拆」。這些以前活在 code review 的腦袋裡、現在搬進可執行規則。
- pre-commit hook 攔住爛 commit——本地直接擋。
- CI gate 兜底——本地 hook 萬一被繞過、CI 上再跑一遍。
- 垃圾回收任務——OpenAI 的進階做法:定期跑後台 Codex 任務、掃整個 codebase、自動開小 PR 償還技術債。AI 寫代碼越快、技術債產生越快、所以清債也必須自動化。
5. 業界頂尖團隊的做法
理論講完,看真實案例。
5-1. Anthropic / Claude Code:跨對話的長任務工程
Anthropic 自己做 Claude Code 是「怎麼讓 Agent 跑幾小時、做完整個 feature」這條的教科書。除了上面 4-3 講過的 Ralph Loop,他們最有洞見的兩個設計:
Context Reset(上下文重置)——Agent 跑久了 context 會塞滿,模型會出現「焦慮」:開始丟細節、忘約束、甚至草率做總結提前結束任務。常規做法是壓縮 context——但壓縮只是變短、模型大腦的「無形負擔」沒消失。
Anthropic 的解法借鏡軟體工程處理 memory leak 的終極手段——重啟進程。當舊 Agent 上下文過載時,啟動一個全新乾淨的 Agent,舊的把關鍵成果和當前狀態「交接」給新的、新的輕裝上陣。
Role Split(生產驗收分離)——同一個 Agent 既寫代碼又給自己打分,會陷入自我感覺良好。Anthropic 把任務拆成三角色:
- Planner——把模糊需求擴成完整技術規格
- Generator——具體寫代碼
- Evaluator——當 QA、有獨立權限跑頁面、模擬用戶、驗證實際結果
「生產跟驗收必須分離」這條是 Anthropic 反覆強調的鐵則。
5-2. OpenAI / Codex:對 AI 重構整個開發環境
OpenAI 3 個人 5 個月用 Codex 寫 100 萬行代碼、合併 1500 個 PR 那個案例背後,最關鍵的不是模型多強——是他們提出一個工程理念叫「Codex legibility」。
直譯是「對 Codex 可讀」。意思是未來 codebase 不只要給人讀、也要給 Agent 讀。原本只給人類工程師用的所有基礎設施(log / 監控 / 除錯工具 / 本地環境),都要被改造成 AI 能直接用的形式。
OpenAI 具體做了 5 件:
- 每個 git worktree 自動起獨立應用實例——Codex 改動時,分支自動起個獨立 dev server。AI 自己開、操作、看反應、驗證改動。
- Chrome DevTools Protocol 接進 Agent runtime——讓 AI 在瀏覽器層有跟工程師一樣的除錯能力:看 DOM、聽網路請求、注入 JS、截圖。
- log / metrics / trace 開放 AI 查詢——讓 Codex 直接用 LogQL / PromQL / TraceQL 查 production 監控資料。排查問題不用工程師手動貼 log,AI 自己 grep。
- 架構約束寫成 linter 規則——「哪一層不能呼叫哪一層」「哪個 naming 必須統一」全部寫成可執行檢查。
- 後台垃圾回收任務——定期跑 Codex 掃 codebase、找偏離架構的地方、自動開 PR 修。
核心理念:把開發環境改造成 AI 可讀、可操作、可驗證的工作台。
5-3. Martin Fowler 的中立觀察
Martin Fowler 親自寫了一篇 Harness Engineering for Coding Agent Users——他把這個詞推進主流工程社群。
他的判斷可以濃縮成一句:好的 Harness 有 4 個屬性——
- Open(開放):你能讀 Agent 讀到的每個檔案、沒有黑箱
- Inspectable(可審查):每一步決策都有記錄、可重現
- Multi-agent ready(多 Agent 友好):同一套 Harness 能跑 Claude Code、Codex、其他任何 Agent
- Mechanism-based(機制導向):靠 hook / linter / CI 強制品質、不靠 prompt 哀求
如果你的 Harness 是 vendor 鎖死、不能換 Agent、靠 prompt 撐品質——那它早晚會崩。
6. 3 個容易踩的反直觀坑
理論看起來簡單,但實作時很容易踩這 3 個坑:
坑 1:Harness 不是越多越好
直覺:工具越多 AI 越強。實際:工具越多、模型每一步選擇空間越大、選錯機率越高。
上面 Vercel 80% → 100% 是直接證據。Manus 也觀察到同樣規律——「一個 heavily armed agent 會變笨」。
判斷標準:每接一個工具前問「它解決的具體行為缺口是什麼?」答不上來就先不接。
坑 2:上下文怎麼組織,比上下文有多大重要得多
很多人看到「Opus 4.7 有 200K context」第一反應是「那就全塞」——這是個昂貴誤解。
Chroma 研究院做的 Context Rot 研究:18 個主流模型在長 context 下表現持續變差。同樣任務、把 context 從 1 萬 token 加到 50 萬 token,性能反而顯著下降。
Stanford 的 Lost in the Middle paper 也證明:模型對 context 頭尾用得最好、中間容易漏。
加上經濟學——Manus 數據:Agent 任務的 input/output token 比約 100:1,KV-cache 命中跟未命中價差 10 倍。同一個任務、context 組織得讓 cache 能重用,每月 API 帳單能差一個量級。
上下文設計是工程問題、不是「全塞讓模型自己挑」。
坑 3:Harness 應該隨模型進化「精簡」、不是堆積
每個 Harness 元件背後都有一個隱含假設:模型自己做不到這件事、所以加外部補丁。
但模型在快速進步、舊補丁可能已經過期。
Anthropic 親自講過案例——早期 Claude Code 加了個強制「規劃」步驟,要求 AI 動手前先輸出計畫。後來某版 Claude 之後,這能力已內化到模型——外置的規劃步驟反而變成冗餘開銷。Anthropic 直接刪掉。
好的 Harness 是在模型能力邊界外、保持剛剛夠用的厚度。每次模型升版後回頭審視你的 Harness——哪些還在補能力?哪些只是歷史包袱?
7. 你今天就能做的 3 件事
讀到這就該動手。今天 30 分鐘做這 3 件事:
1. 開一份 AGENTS.md(或 CLAUDE.md)
在你的 repo 根目錄寫一份 100 行內的「專案地圖」:
- 技術棧(含你用的版本)
- 目錄結構(每個資料夾一句話)
- 禁止事項(不要 commit 進 main、不要改 production schema 不發 RFC)
- commit 前必跑的指令(
npm test && npm run lint) - 風格禁區(不要用 emoji、不要用某些套件)
這份檔案是你 Agent 一切的起點。AI 看不到 AGENTS.md = 它就是裸奔。
2. 加一條 PostToolUse Hook 跑你的測試
6 行 config 的事。Anthropic 自己說這是「單次最高槓桿的可靠性投資」。
任何時候 AI 改了你的 source file——hook 自動跑 npm test(或 pytest、go test、cargo test 任一個)。沒過、AI 必須修。
這把「AI 自信說修好但實際沒跑通」這個常見故障直接從根源解決。
3. 開一份 progress.md
下次你開長任務前——讓 AI 先寫一份 progress.md,紀錄:
- 當前要做什麼(功能清單)
- 已完成(每完成一個就 check)
- 未完成(按優先級排序)
- 已知問題 / 未解 bug
- 關鍵架構決策(為什麼這樣做)
每完成一個 feature 就更新一次。這份檔案是你的 Agent 跨對話的記憶——下次新對話開頭叫它讀 progress.md,它能立刻進入狀態,不用你 brief。
8. Harness Engineering = 新時代工程師的基本功
寫到這裡有件事必須講清楚。
Harness Engineering 聽起來像個新詞——但它本質是把傳統軟體工程的方法學系統化遷移到 AI 工作流上:
| Harness 元素 | 對應的傳統工程 |
|---|---|
AGENTS.md |
需求文件 + 設計文件 |
| 任務編排 | 敏捷迭代拆分 |
| 反饋機制 | 單元測試 + code review |
| 架構護欄 | 代碼規範 + 安全審查 |
| 上下文管理 | 文件管理 + 知識庫 |
這些本來就是優秀工程師的基本功。只是把它們搬到 Agent 的工作環境裡用。
也意味著一件事:做 AI 應用的工程師、過去軟體工程訓練扎實的、現在價值會被放大。AI 取代了「翻譯工」之後——真正稀缺的是「能讓 AI 持續做對的人」。
下次你的 Agent 又把事搞砸——回頭看你的 Harness 在 5 個維度上各自是什麼狀態。
絕大多數情況下,AI 已經夠聰明。缺的是能好好操控它的韁繩。
常見問題
Q:我沒寫過 Claude Code、Codex,這篇對我有用嗎?
A:有。文章談的是「概念框架」——5 個維度、3 個反直觀坑、業界做法。你用任何 Agent 工具(包括自己用 LangChain / LlamaIndex / 純 API 自建)都套得上。具體實作的工具差很多、但思維模型是共通的。
Q:Harness Engineering 跟 prompt 工程差在哪?
A:Prompt 工程是「怎麼把任務說清楚」——一次性指令層級。Harness Engineering 是「怎麼讓模型在多步驟執行中持續做對」——系統工程層級。Prompt 解決「模型聽懂了嗎」、Harness 解決「模型還記得嗎、它跑哪去了、出錯了能不能自己回來」。包含關係:Harness 把 Prompt 跟 Context 都包在裡面。
Q:要不要學?學起來會不會被淘汰?
A:要學、不會被淘汰。模型版本(GPT-5.5 / Opus 4.7 / Gemini 3 Pro)會迭代——但「把 5 個維度設計好」這套判斷力會一直有用。具體技術細節(哪個 hook 怎麼寫、哪個 MCP 怎麼接)會變,結構性判斷不會變。
Q:這跟 DevOps 是同一群人嗎?
A:技能 overlap 高(自動化、CI / CD、監控、log 設計),但目標物件不同——DevOps 服務「人類工程師團隊 + production 系統」,Harness Engineering 服務「AI Agent 在你產品裡的可靠執行」。實務上兩個角色經常合併——一個資深 DevOps 加一點 LLM 知識就能上手 Harness、反之亦然。
Q:模型每幾個月換一次、我的 Harness 會不會白搭?
A:不會。但會需要定期精簡——這是 CH6 坑 3 講的點。每次模型升版後審視你的 Harness:哪些補的能力已被模型內化、可以刪?哪些新能力出現、需要加新工具?Harness 是會呼吸的系統、不是一次寫死的設定檔。
Q:實作上哪些工具最值得我先學?
A:3 個入門首選——
- Claude Code(或 Codex)內建的 hook 機制——pre/post tool use、6 行 config 就能跑驗證
- MCP(Model Context Protocol)——讓你 Agent 串 DB / 搜尋 / 自家工具的標準
- Anthropic 的
claude-coderepo(含plugins/ralph-wiggum範例)——直接抄官方範本起步
Q:團隊裡誰該負責 Harness?
A:正在做 AI Agent 落地的應用工程師——不需要等公司開新職位。如果你的團隊在做 Agent 產品、產品在 production 跑得不穩、bug 修不完——這就是你該補的能力。把 Harness 當成你工程能力的一部分、不是別人的工作。
延伸資源
- walkinglabs / learn-harness-engineering(12 堂課 + 6 個專案 + 範本,最完整的入門課程)
- Martin Fowler | Harness Engineering for Coding Agent Users(中立觀察 + 4 個好 Harness 屬性)
- Anthropic | Claude Code 工程設計(含 Ralph Loop)
- OpenAI | Codex legibility 工程實踐
- ai-boost / awesome-harness-engineering(業界資源彙整)
- 前篇延伸閱讀: