為什麼你的 AI 需要一個記憶——GBrain 個人化 AI 知識庫完整入門

為什麼你的 AI 需要一個記憶——GBrain 個人化 AI 知識庫完整入門
你跟 ChatGPT 講過 100 次的事,下次新對話它還是不知道。
你硬碟裡躺著 500 篇 markdown 筆記,但 AI 一篇都找不到。
你三個月前怎麼決定一個產品方向、你經營過的客戶、你昨天讀完那本書的重點——全在你電腦裡,但你的 AI 看不到。
大部分人把 AI 當「更聰明的 Google」。但真正的個人化 AI 不是這個——是有記憶的同事。是知道你過去說過什麼、做過什麼、決定過什麼、然後在你今天要做新決策時,幫你把過去那些拉出來給你看。
這篇我會講清楚:誰需要個人化 AI、它真正能做什麼、為什麼 GBrain(Y Combinator CEO Garry Tan 4 月開源的工具)是 2026 年最值得認識的解法、以及我自己半年下來的實戰心得。讓我們開始吧。

1. 失憶的 AI vs 有記憶的 AI
先把核心觀念說清楚。
你現在用的 ChatGPT、Claude、Gemini——它們本身沒有跨對話記憶。每次你打開新對話,它都不記得你昨天問過什麼、你三個月前下了什麼決策、你的客戶是誰、你的產品在哪。
| 失憶的 AI(現狀) | 有記憶的 AI(個人化) | |
|---|---|---|
| 上下文 | 限於這次對話 | 你過去寫過的全部 |
| 你要做的事 | 每次重新解釋背景 | 直接問問題 |
| 它能幫你的事 | 知識性回答 | 知識 + 你的脈絡 |
| 對你的價值 | 更聰明的搜尋 | 真的像同事 |
差別在哪?「同事」這個詞是關鍵——
- 你跟一個合作三年的同事,不用每次解釋公司怎麼運作、客戶是誰、產品歷史
- 你跟一個新人,每次都要從零 brief
- 失憶的 AI 永遠是新人。個人化 AI 是合作三年的同事
把 AI 從新人升級成同事——這就是個人化 AI 的核心。
2. 誰會需要個人化 AI?(5 類人)
不是每個人都需要。我把真正會有感的人拆成 5 類——你大概會在其中一兩個位置看到自己。
寫作者 / 內容創作者
你寫過 50 篇部落格、200 條 Threads、各種草稿。每次想寫新東西,你模糊記得「我以前好像寫過這個」——但找不到、或想重新切角又怕跟舊文撞。
個人化 AI 能:「你上週寫的 Codex 入門,我這篇 Harness Engineering 有沒有跟它重複的點?」、「幫我找我寫過所有關於 Threads 演算法的觀點」。
創業者 / PM
你的客戶名單、產品決策、團隊規範、過去踩過的雷——全散在 Notion、Slack、Email、Google Docs、會議記錄、你自己的 markdown 裡。
個人化 AI 能:「這個客戶之前提過什麼需求?」、「我們上次定 pricing 的脈絡是什麼?為什麼選了 $20 不是 $30?」、「這個 feature 我們半年前討論過要做嗎?結論是什麼?」
知識工作者 / 研究者
你讀過 100 本書、研究過 30 個議題。每個議題都有筆記、有引用、有自己的 take——但散在不同檔案、不同主題互相關聯但你找不出來。
個人化 AI 能:「我讀過所有關於 AI agent 的書,把它們的核心觀點整理成一張對照表」、「我之前研究 Vibe Coding 的時候,跟現在這個 Harness Engineering 議題有什麼可以延伸的?」
經理 / 投資人
你管理 30 個下屬、追蹤 50 家公司、跑過幾百次會議。每個人、每家公司、每次互動都有 context——你心裡記不住全部,腦袋越來越擠。
個人化 AI 能:「這家公司上次見面是什麼時候?我們聊了什麼?」、「幫我把 A 同事過去半年所有 1-on-1 的關鍵點整理出來」、「這家新創跟我們投過的哪幾家有相似性?」
自媒體經營者
你經營 IG / Threads / YouTube。每天有想法、有觀察、有對讀者反應的觀察。但內容越來越多、你開始重複自己、找不到老梗、無法系統化你的「個人觀點地圖」。
個人化 AI 能:「我過去 3 個月在 Threads 上提過哪些觀點?哪些反應好哪些反應差?」、「這個新題目跟我以前寫過的相似嗎?該用什麼角度切才不撞舊文?」

3. 個人化 AI 可以做什麼?4 種真實應用
職業講完,講具體場景。
應用 1:追溯歷史——「之前我們怎麼決定的?」
最強、也最直接的應用。
任何過去做過的決策、聊過的話、寫過的東西——你用自然語言問:「這個產品 pricing 怎麼定的?我上次說過什麼?」AI 自動翻你的 vault、找到當時的會議記錄、決策檔、討論串,用一段話總結原因。
過去做這件事要你開三個工具:Notion 翻、Email 搜、Slack search。現在一句話。
應用 2:跨筆記關聯——「pricing 的脈絡是什麼?」
更進階的——不只是找一個檔案,是跨多個檔案找關聯。
「我們 Redia 國際定價是怎麼來的?」——AI 同時讀:你過去 6 個月所有 pricing 相關決策、所有客戶反饋、所有對手分析、所有你自己的反思。用所有這些當 context、給你一個整合答案。
這條是傳統 RAG(檢索增強生成)的甜蜜區,但 GBrain 加上了 knowledge graph——它知道「pricing」這個概念在你 vault 裡跟「Redia」、「TWD」、「stripe」、「對手 X」這些 entity 是怎麼連的,檢索精準度比純向量 RAG 高很多。
應用 3:套用個人原則——「按我過去判斷」
這條最深、也最少人用。
每個有經驗的人腦袋裡都有一套「我過去怎麼判斷類似情況」的原則。但你寫進筆記的多半是結論、不是原則本身。
個人化 AI 能:「我現在猶豫要不要做 X,根據我過去半年所有類似決策的脈絡幫我判斷」——AI 翻你 vault、找過去類似情境、抽出隱含的判斷模式,用「你過去的你」說話。
我自己用這個用得最深的場景:廣告投放決策。我設了一條原則「決策必須配對量化預測」——AI 在我每次問廣告問題時,會自動套這條原則檢查我有沒有想清楚。
應用 4:自動 ingest 你的人生
GBrain 最高槓桿的用法不是「查」,是「寫」。
Garry Tan 自己 production 跑的版本:自動化 cron jobs 在他睡覺時自動 ingest 會議記錄、Email、tweets、voice notes、Slack 訊息——全部變成可搜尋的 markdown 進 vault。
意思是你不用「主動」寫筆記。你只要說話、會議、寫信、發推、發 Slack——這些都自動變成你個人化 AI 的記憶。
醒來後 vault 多 30 個新檔案、AI 已經 index 完。你直接問問題。
4. GBrain 是什麼?為什麼這個爆紅
主角登場。
GBrain 是 Y Combinator CEO Garry Tan 在 2026/4/5 親自開源的 AI agent 記憶系統。
它的定位很精準:「把你的 markdown 筆記變成 AI agent 能讀、能寫、能推理的知識圖」。MIT license 開源、24 小時拿 5000 GitHub stars、迅速變成業界談個人化 AI 的標竿。
為什麼這個爆紅?三個關鍵:
- 不是另一個 RAG 教學——是 Garry 自己 production 跑的系統。他自家 vault 跑了幾萬篇 markdown 頁面、上千個人物頁、上百個公司頁、加上一群 autonomous cron jobs 邊睡邊 ingest
- 2 秒啟動——預設用 PGLite(embedded Postgres、WASM 跑)、不用 Docker、不用 server、不用 connection string。
gbrain init然後就有 brain 了 - 明確的成本可控——支援 16 個 embedding provider,含 OpenAI / Voyage / 自家 Ollama(本機跑、不外送)。你可以選「全雲端」也可以選「整套離線本機跑、零 API 費」
我自己選的是後者——本機 Ollama 跑 bge-m3 embedding,1024 維、繁中支援、零 API 費。整個 vault 半年下來 embedding 完全沒花一毛錢。
5. GBrain 5 個關鍵設計
這節對工程師讀者深一點。普通讀者可以跳到 CH6。
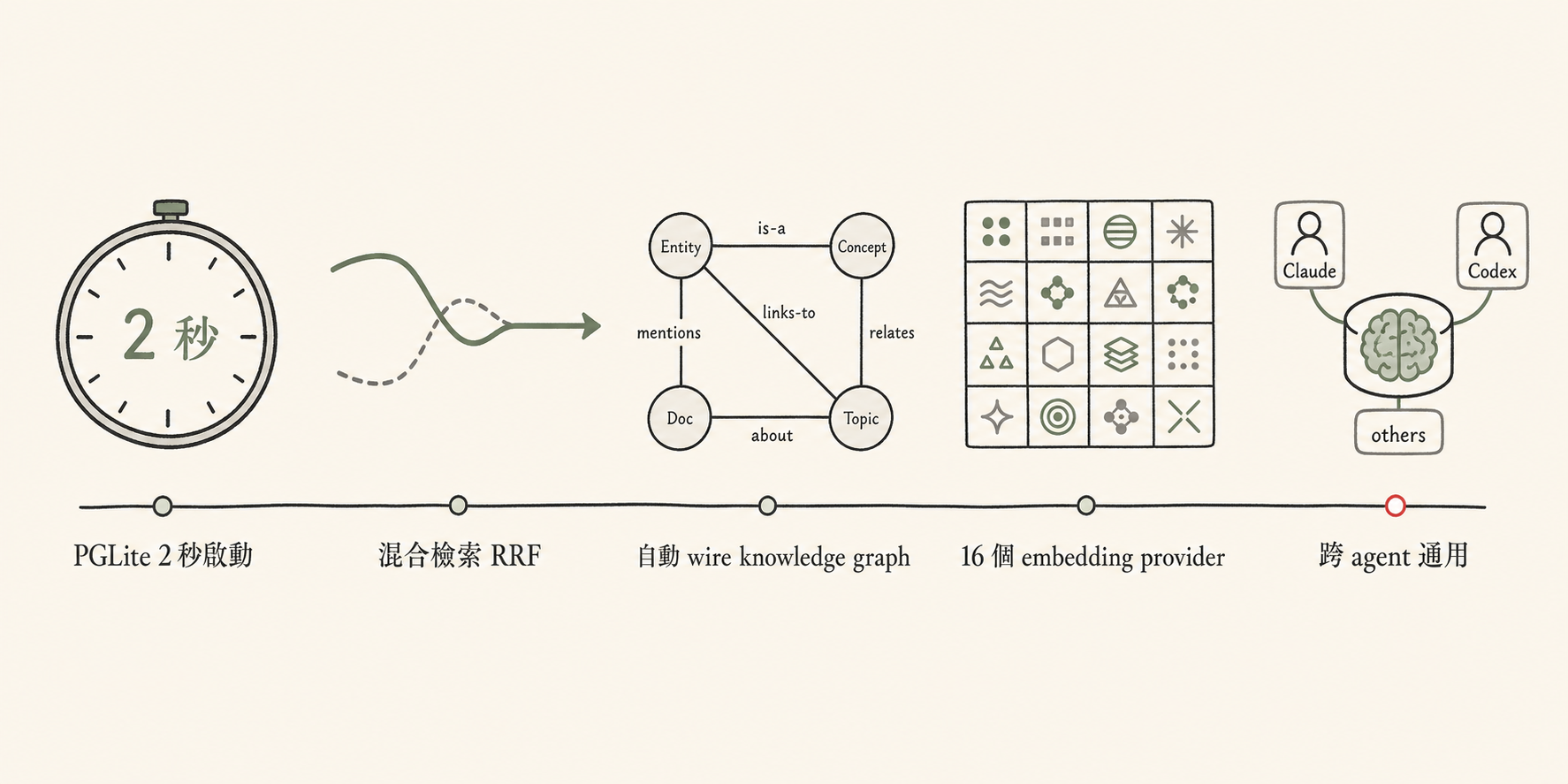
設計 1:PGLite 2 秒啟動
過去自架知識庫要先 setup Postgres / Pinecone / Weaviate / 自己跑 server。GBrain 直接用 PGLite——embedded Postgres 17.5 透過 WASM 跑——你的 brain DB 就是一個 brain.pglite 檔案、跟 SQLite 一樣放在你 home 目錄。
gbrain init → 2 秒拿到一個完整 Postgres 環境、可以做 vector + tsvector + JSON 操作。零外部依賴、零設定成本。
設計 2:混合檢索 + RRF 融合
GBrain 不是純向量檢索。它同時跑兩種:
- HNSW vector search(用 embedding model 跑語意相似)
- Postgres tsvector(純 keyword 找 exact match)
然後用 Reciprocal Rank Fusion(RRF) 把兩個結果融合。為什麼這樣設計?因為純向量 RAG 有個老問題——找不到 exact entity(你問「Redia」,向量搜出來可能是「pricing 相關概念」這種糊糊的東西)。加 keyword 把這條補上。
實測 Recall@5 從純向量的 83% 拉到 RRF 的 95%。
設計 3:自動 wire knowledge graph
這條最聰明。
每次你 write 一個 markdown 頁、GBrain 用 regex 自動抽 entity 並建立 typed link(例如 works_at / invested_in / founded)。完全不調用 LLM——所以零 API 費、毫秒級。
意思是你 vault 不用手動 wiki-link(像 Obsidian 的 [[entity]] 那樣)——只要寫純自然文字、entity 會自動被識別、自動連起來。
設計 4:16 個 embedding provider
對隱私 / 成本敏感的人,這條是關鍵。
你可以選:
- 全雲端(OpenAI / Voyage / Google)——品質頂、花錢、外送資料
- 半本機(OpenRouter / Azure)——可以選企業合約版
- 全本機(Ollama / llama.cpp)——零 API 費、零外送、品質略低但夠用
我選 Ollama 跑 bge-m3——這個是中文社群最常推薦的本機 embedding model、1024 維、繁中表現意外好。
設計 5:跨 agent 通用
GBrain 不綁定特定 AI——Claude Code、Codex、自家寫的 agent、其他 MCP-compatible 工具都能讀寫。
意思是你 brain repo 是「你的 source of truth」——你今天用 Claude Code、明天換 Codex、後天接新工具,brain 不用搬家。
這條對長期使用者太關鍵——AI 工具年年換,你的記憶不該跟著遷徙。
6. 跟 Obsidian / Logseq / Notion AI 怎麼選?
GBrain 不是要取代你的筆記工具,是接在筆記工具下面當 AI 介面。
| Obsidian / Logseq | Notion AI | GBrain | |
|---|---|---|---|
| 本質 | 筆記工具 | 雲端工作區 + AI | AI agent 記憶系統 |
| 主要用法 | 你自己讀寫 | 你寫、AI 問答 | AI 讀寫推理、你自然語言問 |
| 隱私 | 本機 | 雲端 | 可全本機 |
| 跨 AI 通用 | 用插件 | Notion AI only | 跨任何 agent |
| 學習曲線 | 中 | 低 | 要點命令列 |
| 適合 | 喜歡自己整理筆記 | 團隊 | AI 重度用戶 |
簡單版選法:
- 你只想要好用筆記 → Obsidian / Logseq
- 你公司多人協作 → Notion AI
- 你常常跟 AI 對話、想讓 AI 知道你過去說過什麼 → GBrain
而且這幾個不衝突——你可以用 Obsidian 寫筆記、Logseq 做 daily note、然後把整個 vault 註冊為 GBrain source——AI 同時讀得到。
7. 實戰:30 分鐘建好你的第一個 GBrain
放心,這節我寫得超低門檻。不用碰雲端、不用 API key、不用 Docker。
Step 1:安裝(5 分鐘)
GBrain CLI 用 Bun(一個比 Node 快 5 倍的 JS runtime)。如果你沒有 Bun:
curl -fsSL https://bun.sh/install | bash
然後 clone GBrain:
git clone https://github.com/garrytan/gbrain ~/gbrain
cd ~/gbrain && bun install
裝完 ~/gbrain/bin/gbrain 就是你的 CLI。建議加到 $PATH。
Step 2:建立你的 brain repo(5 分鐘)
挑一個資料夾當你的「brain」——可以是新空目錄、也可以是你既有的 Obsidian vault。
cd /path/to/my-brain
gbrain init
這會:
- 建立
.gbrain-source標記檔 - 初始化 PGLite DB(在
~/.gbrain/brain.pglite) - 寫一份預設
config.json
Step 3:把現有 markdown 倒進去(10 分鐘)
如果你已經有 markdown 筆記——把它們複製到這個資料夾就好。GBrain 不挑結構,任何 .md 都吃。
我的建議 MECE 目錄結構:
my-brain/
├── people/ # 人物
├── companies/ # 公司
├── projects/ # 進行中專案
├── concepts/ # 知識點 / 你的觀念
├── logs/ # 會議記錄 / 對話紀錄 / 日記
└── README.md # 整個 brain 的索引
Step 4:跑第一次 embed(5 分鐘)
這步把所有 markdown 算 embedding 進 DB:
gbrain embed --stale
第一次跑會把全部跑一遍。預設用 OpenAI(要 API key)——進階:本機 Ollama 不外送請見 GBrain README,文章篇幅有限不展開。
Step 5:第一次 query(5 分鐘)
完成。現在你可以問:
gbrain query "我過去三個月關於 X 的決策有哪些?"
或更日常的用法——接 Claude Code / Codex。在你 Claude Code 的 CLAUDE.md 加一條:
有問到既有 vault 內容、跨專案脈絡、歷史決策時,先跑 `gbrain search "<query>"`、再決定要深讀哪些檔案。
之後你跟 Claude Code 對話、它會自動跑 gbrain、自動讀對的檔案、用對的 context 回答你。
8. 我自己半年實戰的設定
理論+教學講完,講我自己怎麼用。
我半年前把整個 personal-system vault 註冊成 GBrain source。personal-system 是我自己的「思考 + 專案 + 決策」總倉庫——裡面有:
me/我的身份、原則、決策風格projects/進行中的所有專案(meta-ads、blog、redia、課程平台、stripe、threads-radar...)logs/對話紀錄、stuck 卡關、研究 notes.agents/skills/自己寫的 agent skills
半年用下來,4 個關鍵設定:
1. 本機 Ollama、零外送
我選 ollama:bge-m3 當 embedding——本機跑、繁中支援好、1024 維。整個 vault 半年 embed 過數次,沒花一毛錢 API 費。
對處理客戶資料、合約、創業敏感資訊的人——這條是底線。
2. 自然語言介面、不記 CLI
我自己幾乎不用 gbrain search / gbrain query 這些命令列。取而代之,我在 CLAUDE.md 寫了一條規則:
「Ray 不需要記 gbrain CLI。Ray 只要用自然語言問:『之前怎麼決定的?』、『幫我找 Redia pricing 的脈絡』、『根據我過去原則判斷這件事』;Agent 必須自行判斷是否需要跑 GBrain。」
之後我跟 Claude Code 對話、它會自己判斷該不該跑 GBrain、跑什麼 query、然後深讀對的檔案、用人話回答。
3. 跨專案脈絡查詢
最強的場景:我同時做 4 個產品(meta-ads、redia、課程平台、blog)。每個產品的決策、教訓、客戶都散在不同目錄。
我問:「我過去半年所有產品定價決策的共同模式是什麼?」——Agent 自動跑 GBrain、找出 meta-ads、redia、課程三個專案的 pricing 決策、用一段話告訴我我有什麼隱含 pattern。
這條讓我發現好幾個自己沒意識到的盲區。
4. 跨對話 + 跨日的記憶
最長壽的價值是這個——
Claude / ChatGPT 每次新對話都失憶。但有了 GBrain、Agent 每次新對話前都會自動 query 一遍我 vault 的相關脈絡。
意思是即使我這個對話是新開的——AI 依然知道我前天決定的事、上週的客戶名單、上個月的學習筆記。從新人升級成同事的瞬間就是這個感覺。
9. 3 個容易踩的坑
天下沒有完美工具。
坑 1:筆記不夠多時搜尋品質差
業界共識:< 200 篇筆記 retrieval 開始有用,500-1000 篇 connection discovery 才開始有價值。
如果你 vault 才 30 篇——GBrain 給你的東西不會比 grep 強多少。先寫筆記、再上 GBrain,順序不要顛倒。
「需要寫多久才會 200 篇?」業界經驗:一個正常工作的人持續寫,6-8 週可以累積 200 篇可用筆記。
坑 2:沒目錄結構就是一坨
GBrain 不挑結構,但「全部丟在一個資料夾」會嚴重降低檢索品質——因為 typed link 抽取需要 context(你筆記放在 people/ 還是 concepts/ 影響 entity 怎麼解讀)。
至少建好上面提的 MECE 目錄(people / companies / projects / concepts / logs)。
坑 3:沒設 README resolvers Agent 不知道怎麼寫
GBrain 強大的點之一是**「AI 能寫進你的 brain」**——比如自動把今天會議記錄加進 people/王小明.md。但要做到這件事、每個目錄要有 README.md、告訴 AI「這個目錄的檔案應該怎麼命名、什麼內容該進這目錄」。
我自己一開始沒設、結果 Agent 把會議記錄丟得到處都是。設完之後乾淨很多。
10. 你週末就能做的事
不要把這篇收藏完就關掉。
今天就花 30 分鐘做這 3 件事:
- 裝 GBrain(5 分鐘)
- 挑一個你已有的 markdown 資料夾跑
gbrain init(5 分鐘)——可以是 Obsidian vault、可以是空的、可以是你 Notes app 匯出的 - 問第一個問題(20 分鐘 — 因為你會玩上癮):
- 「我過去 3 個月寫過什麼?挑 5 個最重要的觀點」
- 「我有哪些重複的觀點?哪些已經改過想法?」
- 「找一個我以前討論過但沒推進的題目」
如果你 vault 不夠 200 篇——今天就開始累積。AI 工具年年換、模型半年改、你自己寫的筆記才會跟著你十年。GBrain 是讓這些筆記終於開始「對你的 AI 有意義」的工具。
常見問題
Q:要不要付費?GBrain 本身免費嗎?
A:GBrain 本身完全免費開源(MIT license)。費用來自 embedding provider 的選擇——選 OpenAI 要 API 費(embedding 很便宜,幾萬篇 markdown 約 $5-15 一次);選 Ollama 本機跑、零費用。
Q:我筆記裡有客戶資料、合約、敏感資訊,可以用嗎?
A:可以,但選對 embedding provider。Ollama 本機跑 = 全程不外送,最安全。OpenAI / Voyage 雲端版會傳資料給他們。商業敏感資料強烈建議走 Ollama。
Q:可以跟 Obsidian 共用同一個 vault 嗎?
A:完全可以、而且推薦這樣用。把你 Obsidian vault 跑 gbrain init、再裝 Obsidian——兩個工具看的是同一份 markdown,Obsidian 給你寫、GBrain 給 AI 讀。我自己就是這樣用。
Q:多少筆記才開始有用?
A:200 篇開始有用、500-1000 篇開始驚艷、3000+ 篇是「整個第二大腦」的感覺。如果你還不到 200 篇,先寫再說、不要花時間調 GBrain 參數。
Q:中文 embedding 效果怎樣?
A:用 Ollama bge-m3 處理繁體中文意外好——這是中文社群最推薦的本機 embedding 之一。我自己半年下來查中文 vault、retrieval 品質沒讓我失望過。如果預算夠走雲端、Voyage 的多語模型更頂、但不是必要。
Q:跟 RAG 差在哪?GBrain 就是 RAG 包裝過嗎?
A:底層是 RAG,但加了三件 RAG 沒有的東西——(1) 混合檢索 + RRF(不只純向量、加 keyword)、(2) 自動 wire knowledge graph(regex 抽 entity 建 typed link)、(3) AI 能寫進 brain(不只讀、autonomous 在你睡覺時 ingest 你的人生)。所以 GBrain ≈ RAG + KG + write-back agent。
Q:要會寫 code 嗎?
A:Command line 要敢碰(gbrain init / gbrain embed / gbrain query)——但不需要寫 code。我這篇 7 個指令、複製貼上就能跑完整流程。
Q:以後 AI 模型換了、我的 GBrain 還能用嗎?
A:能。這是 GBrain 最強的點之一——brain repo 是 markdown + Postgres、跟特定 AI 模型完全解耦。你今天用 Claude Code、明天換 Codex、後天接新工具,brain 不用搬家、只要換接的 AI agent。
延伸資源
- GBrain GitHub repo(garrytan/gbrain)(MIT license、5000+ stars)
- GBrain Setup Guide by Vibe Sparking AI(社群最完整的中英文入門)
- Building a Private Karpathy-Style LLM Wiki With gbrain(進階:把 GBrain 加進工程工作流)
- Ollama bge-m3 model(中文本機 embedding 首推)
- 前篇延伸閱讀:
- Harness Engineering:做 AI 產品工程師必須得知道的新技能——GBrain 是 5 維度裡「記憶」的解法
- Claude 寫文 + Codex 配圖——分工 + 記憶 = 完整 AI 工作流