打造你的第一個 MCP Server:從概念到實作

📅 發布時間: 2025-10-23
🏷️ 標籤: MCP, AI Agent, Node.js, Express, ngrok, ChatGPT, Claude
想讓 AI 助手存取你的本地筆記、檔案或資料庫?本文從實際痛點出發,完整解析 MCP(Model Context Protocol)如何成為 AI 與工具溝通的標準協定。透過手把手的程式碼教學,帶你打造第一個 MCP Server,讓 ChatGPT 或 Claude 能自動讀取你的個人知識庫。包含完整實作、ngrok 部署步驟與實際對話測試,讓你快速掌握 AI Agent 開發的核心技術。
開場:為什麼需要 MCP?從真實痛點出發
你是一位熱愛學習的工程師,這些年累積了超過 1000 篇個人筆記,散落在本地資料夾裡。涵蓋前端框架、後端架構、演算法、系統設計⋯⋯每一篇都是你花時間整理的寶貴知識。
某天,你想問 ChatGPT:「幫我找所有關於 React Hooks 的筆記,並整理出我還沒掌握的進階用法。」
這個需求聽起來很合理,對吧?但實際上,要讓 AI 助手做到這件事,困難重重。

圖: AI 對大檔案感到困難重重
現有方案都不夠好
讓我們快速看幾個現有的處理方式:
手動複製貼上? 效率極差,每次都要重複,而且 AI 只能看到你貼的部分,無法主動探索更多相關筆記。
批次上傳檔案? 跟剛剛一樣的問題,你得先猜哪些檔案相關,容易遺漏,而且每個新問題都要重新上傳。

圖: 手動貼上一堆檔案很麻煩
用 Claude Code 或 Cursor? 它們的能力被綁死在特定工具裡,而且這些工具就是很會 Coding,不太會討論、發想創意。更重要的是,缺乏標準化 —— 每個工具都自己搞一套。
圖: Claude 工具限制
寫個 REST API? 這是最接近的方案,但有個致命問題:REST API 是為「程式」設計的,不是為「LLM」設計的。 LLM 不知道你有哪些 API,需要每次對話都重新被告知規格,還得自己猜該呼叫哪個 endpoint。
這就是 MCP 要解決的問題。
MCP 是什麼?AI 義肢製作手冊
不知道你有沒有看過 Cyberpunk 2077?
在這個世界觀上,大部分的人都會安裝一推超酷的義肢,更強壯的手臂、更壯的機械腿...,但這些義肢要能正常運作,有個前提:義肢的接口必須符合標準規格。如果每個義肢廠商都自己搞一套接口,那你的手臂根本裝不上去。
MCP 就像是一本「AI 義肢製作手冊」。
ChatGPT、Claude 這些 AI 會根據這本手冊打造對應的「安裝槽」,而任何人都可以根據這份手冊,設計給 AI 使用的「義肢」,然後直接裝上去。
重點來了:MCP 只是一本製作手冊,用嚴謹的話來講就是:
- AI 與工具溝通的標準協定
- 讓 AI 能自動發現工具的機制
- 標準化的權限和安全邊界
它只決定「接口的部分長怎樣」,確保你做出來的義肢可以順利裝到其他 AI 身上。至於這個義肢有什麼功能?讀檔案、查資料庫、發 email、控制你的智慧家居⋯⋯隨便你,完全自由。
與 REST API 的差異
MCP 是為 LLM 設計的標準化協定,讓 AI 能夠自動發現和使用你的工具。
關鍵差異:
| 特性 | REST API | MCP |
|---|---|---|
| 設計對象 | 給「開發者」用 | 給「LLM」用 |
| 發現機制 | 需要讀文件 | AI 自動發現工具 |
| 使用方式 | 需要寫程式呼叫 | AI 自動選擇並呼叫 |
| 參數格式 | 需要查文件 | 設計 MCP 時,都會定義好 |

圖: MCP vs REST API 比較
在提到 MCP 之前,必須得提一下什麼是 「Agent」?
這裡快速釐清一下概念。
AI(嚴格來說是 LLM)就是一個只會思考、無法行動的大腦。
對,他只是一顆大腦,沒手沒腳,無法行動。他可以思考得很深入、很精彩,但你問他「幫我查一下天氣」,他只能回答「抱歉我查不了」。
那什麼是 Agent 呢
簡單說,Agent = AI 大腦 + 能力(工具)。給 AI 裝上「手」(查天氣的工具)、「腳」(控制智慧家居的工具),他就從一顆只會想的大腦,變成一個能實際做事的 Agent。
MCP 就是定義「怎麼給 AI 裝義肢」的標準。
如果你對 AI Agent 的概念想要更深入了解,推薦閱讀我之前撰寫的書籍《從零開始,打造一個生成式 AI 平台》https://www.books.com.tw/products/0011029234 ,裡頭有更完整的講解。
MCP 的核心概念:Tools — AI 的「義肢」
如果說 AI 的大腦是語言模型,那麼 Tools 就是 AI 的義肢。
沒有義肢,大腦再聰明也只能思考,無法行動。有了 Tools,AI 才能:
- 獲取資訊 — 讀取你的檔案、查詢資料庫、呼叫 API
- 執行動作 — 發送郵件、建立文件、修改資料
- 改變狀態 — 更新設定、記錄日誌、觸發流程
Tools 的三個關鍵特性
1. AI 自己決定什麼時候用
這是 Tools 最重要的特性。你不需要明確指示「請呼叫 XXX 工具」,AI 會根據對話情境自己判斷。
AI 自己決定:
- 什麼時候用工具
- 用哪個工具
- 傳什麼參數
2. Tool 本質就是一個 Function
Tools 就是一個 Function,他執行完後的結果,會送回給 LLM
就像下面這三個 Function
list_notes()→ 返回:[note1.md, note2.md, note3.md]read_note(path: \"note1.md\")→ 返回:筆記的完整內容search_notes(query: \"React\")→ 返回:包含 "React" 的筆記列表和摘要
每個 Tool 的呼叫都會產生結果,AI 會根據結果決定下一步動作。
這就像是你問助理「幫我查一下檔案」,他真的會去翻檔案櫃。
3. 有明確的規格書(Schema-Defined)
每個 Tool 都有清楚的說明書,你必須替每一個工具定義好以下參數
- 工具名稱,這個工具叫什麼
- 工具說明,這個工具是做什麼的
- 輸入參數,這個工具可以傳入什麼,需要提供什麼參數
- 輸出參數,這個工具會回傳什麼
基本上還是剛剛提到的,Tool 的本質就是一個 Function,只是你必須詳細交代 LLM 該怎麼用、什麼時會去用這個 Function
❓ 練習題
你正在開發一個「個人知識庫」的 MCP Server。下列哪個功能「不應該」設計成 Tool?
A) 搜尋筆記內容(根據關鍵字找出相關筆記)
B) 筆記分類規則(說明你如何組織筆記的 markdown 文件)
C) 建立新筆記(在指定目錄建立 .md 檔案)
D) 統計筆記數量(計算各分類有多少筆記)💡 點擊查看解答
正確答案: B
工具是一個 Function,是一個可以被執行的行為。筆記分類規則,其實就是很單純的文字、命令告訴 LLM 該怎麼做。
單選題解析:你正在開發一個「個人知識庫」的 MCP Server。下列哪個功能「不應該」設計成 Tool?
工具是一個 Function,是一個可以被執行的行為
筆記分類規則 ,其實就是很單純的文字、命令告訴 LLM 該怎麼做
目標:實作第一個 Tool:列出所有筆記
我們要解決什麼問題?
現在我們要讓 AI 能夠「看到」你電腦裡有哪些筆記檔案。
這個工具很簡單:
- 輸入:不需要參數(列出所有筆記就好)
- 輸出:每個筆記的名稱 + 路徑
- 目的:讓 AI 知道有哪些筆記可以讀取
第一步,創建一個簡單的 HTTP 伺服器
💻 專案初始化與基本 HTTP 伺服器
🎯 學習目標:初始化 Node.js 專案並安裝必要套件建立 Express 伺服器並設定健康檢查配置 TypeScript 環境與腳本命令
步驟 1: 創建專案資料夾
首先,創建一個資料夾當作專案資料夾。我這邊就叫做「my-notes-mcp-server」。

圖: 創建專案資料夾(寬度 200px,置中)
步驟 2: 初始化專案與安裝套件
npm init -y
npm install @modelcontextprotocol/sdk express zod
npm install -D @types/express @types/node tsx typescript
接下來打開終端機,進入該資料夾中直接貼上這三行命令。
初始化 Nodejs 專案同時安裝必要套件。

圖: 終端機安裝命令(寬度 600px,置中)
步驟 3: 建立基本 Express 伺服器
import express from 'express';
// 1. 建立 Express 應用程式
const app = express();
app.use(express.json());
// 2. 設定路由
// 健康檢查 endpoint
app.get('/health', (req, res) => {
res.json({
status: 'ok',
message: 'Server is running!'
});
});
// 3. 啟動伺服器
const port = 8080;
app.listen(port, () => {
console.log(`🚀 伺服器運行中:http://localhost:${port}`);
console.log(`📍 健康檢查:http://localhost:${port}/health`);
});
創建一個 index.ts。這是一個非常簡單的 HTTP 伺服器。
圖: index.ts 程式碼(寬度 300px,右上)
步驟 4: 配置 package.json 腳本
{
"name": "my-notes-mcp-server",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"dev": "tsx watch index.ts", /* @cat-caption → // [新增] dev 命令:使用 tsx watch 監聽 TypeScript 變更並熱重載,讓開發更高效 */
"start": "tsx index.ts", /* @cat-caption → // [新增] start 命令:直接執行 TypeScript 檔案,適合生產環境啟動 */
"build": "tsc", /* @cat-caption → // [新增] build 命令:編譯 TypeScript 到 JavaScript,提升部署穩定性 */
"serve": "node dist/index.js" /* @cat-caption → // [新增] serve 命令:執行編譯後的 JS,模擬生產部署流程 */
},
"keywords": [],
"author": "",
"license": "ISC",
"type": "commonjs",
"dependencies": {
"@modelcontextprotocol/sdk": "^1.20.2",
"express": "^5.1.0",
"zod": "^3.25.76"
},
"devDependencies": {
"@types/express": "^5.0.4",
"@types/node": "^24.9.1",
"tsx": "^4.20.6",
"typescript": "^5.9.3"
}
}
打開 package.json,簡單設定一下一些常用命令。
圖: package.json 配置(寬度 301px,右上)
步驟 5: 配置 tsconfig.json
{
"compilerOptions": {
"target": "ES2022",
"module": "ESNext",
"moduleResolution": "bundler",
"esModuleInterop": true,
"strict": true,
"skipLibCheck": true,
"outDir": "./dist"
},
"include": ["*.ts"]
}
我打算使用 TypeScript,所以需要創建一個 tsconfig.json,確保 TypeScript 能正確被處理。
圖: tsconfig.json 配置(寬度 300px,右上)
步驟 6: 啟動伺服器測試
OK! 現在在終端機輸入 npm run dev,應該能夠在瀏覽器中打開 http://localhost:8080/health。
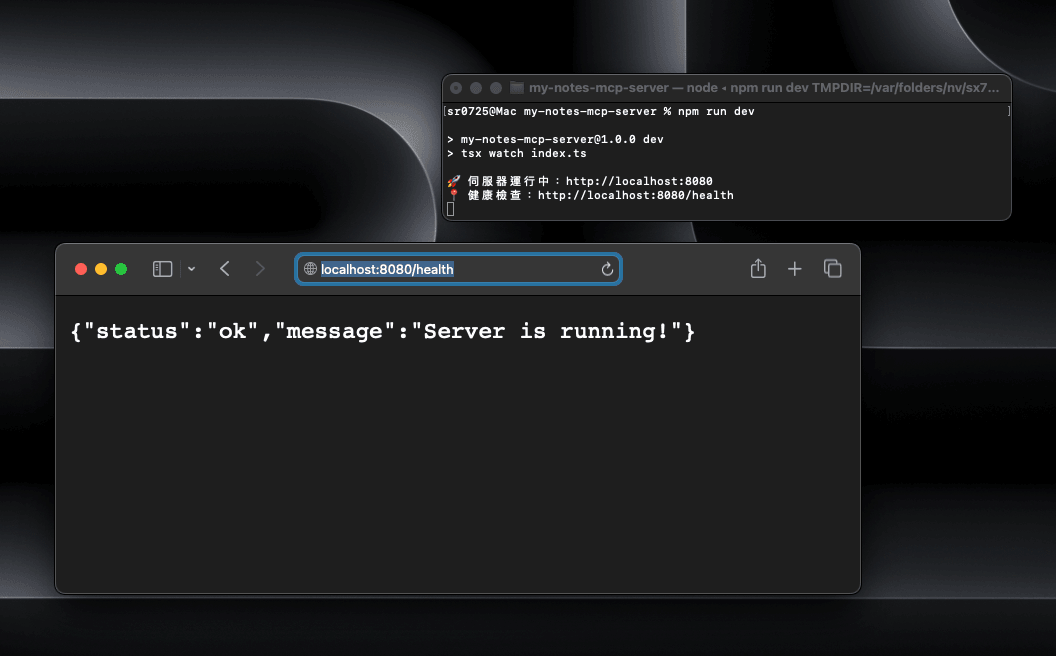
圖: 伺服器健康檢查(全寬)
第二步,開始打造一個最簡單的 MCP 伺服器
💻 建立 MCP Server 與第一個 Tool
🎯 學習目標:匯入 MCP SDK 並建立 McpServer 實例註冊 Tool 包括規格書(Schema)與執行函數設定 MCP endpoint 處理請求理解 content 與 structuredContent 的差異
步驟 1: 匯入 MCP SDK 並建立 Server
import express from 'express';
import { McpServer } from '@modelcontextprotocol/sdk/server/mcp.js'; /* @cat-caption → // [新增] 匯入 McpServer:這是 MCP 協議的核心類別,負責工具註冊、連接管理和訊息路由,讓 SDK 處理底層通訊細節 */
const app = express();
app.use(express.json());
// 建立 MCP Server /* @cat-caption → // [新增] 建立 McpServer 實例:定義伺服器名稱與版本,這些資訊會暴露給客戶端 AI,讓它知道伺服器的身份與相容性 */
const server = new McpServer({ /* @cat-caption → // [新增] 配置物件:name 與 version 是必填,用於客戶端顯示與版本檢查,確保協議相容 */
name: 'my-notes-server', /* @cat-caption → // [新增] name:伺服器唯一識別名稱,直覺描述功能(如「我的筆記伺服器」),AI 會在工具列表中看到 */
version: '1.0.0' /* @cat-caption → // [新增] version:版本號,用於未來升級與相容性檢查,避免舊客戶端連新伺服器出錯 */
}); /* @cat-caption → // [新增] 初始化完成:現在 server 準備好註冊工具並處理連接 */
app.get('/health', (req, res) => {
res.json({
status: 'ok',
message: 'Server is running!'
});
});
const port = 8080;
app.listen(port, () => {
console.log(`🚀 伺服器運行中:http://localhost:${port}`);
console.log(`📍 健康檢查:http://localhost:${port}/health`);
});
首先,創建 MCP Server。他是整個系統的核心,負責連接管理、訊息傳輸、主持著各種各樣的設定記載。
這邊的話只需要定義伺服器的名稱跟版本即可,他會顯示在客戶端上。
步驟 2: 註冊第一個 Tool(名稱)
// ... (前面的程式碼保持不變)
server.registerTool( /* @cat-caption → // [新增] registerTool 方法:MCP SDK 的核心 API,用來註冊工具,讓 AI 能自動發現並呼叫 */
'list_files' // 工具名稱 /* @cat-caption → // [新增] 工具名稱:必須是英文駝峰或蛇形,直覺描述功能(如 list_files),AI 會根據描述自動選擇使用 */
); /* @cat-caption → // [新增] 註冊完成:工具名稱已註冊,但還需規格與實作函數才完整 */
app.get('/health', (req, res) => {
res.json({
status: 'ok',
message: 'Server is running!'
});
});
// ... (後面的程式碼保持不變)
接著,我們就可以來定義第一個工具,讓 AI 能知道並使用他。
mcpServer 提供 registerTool 來註冊一個新工具,必須先傳入工具的名稱,這裡的名稱應當直覺、能夠被 LLM 直接理解他的功能。
步驟 3: 定義 Tool 規格書(Schema)
import { z } from 'zod'; /* @cat-caption → // [新增] 匯入 zod:用於定義輸入/輸出 Schema,提供嚴謹的型別驗證與描述,讓 AI 理解參數格式並自動生成呼叫 */
server.registerTool(
'list_files',
{ /* @cat-caption → // [新增] 規格書物件:描述工具的 metadata,讓 AI 知道工具用途、參數與回傳 */
title: '列出檔案', /* @cat-caption → // [新增] title:工具的人類可讀名稱,用繁體中文描述功能,AI 會在工具列表顯示給使用者 */
description: '列出所有 Markdown 檔案', /* @cat-caption → // [新增] description:詳細說明工具用途與情境,指導 AI 何時使用(如「用來探索筆記庫」) */
inputSchema: {}, // 這裡不需要傳入任何參數 /* @cat-caption → // [新增] inputSchema:空物件表示無輸入參數,zod 確保型別安全,AI 呼叫時無需參數 */
outputSchema: { /* @cat-caption → // [新增] outputSchema:定義回傳結構,讓 AI 預期結果格式並解析 */
files: z.array(z.string()) /* @cat-caption → // [新增] files:字串陣列,描述回傳檔案列表,zod 自動生成 JSON Schema 給 AI */
} /* @cat-caption → // [新增] Schema 完成:這些描述讓 AI 自動理解工具,無需額外文件 */
},
);
再來, registerTool 的第二個參數傳入該工具的規格書。
- title,這個工具叫什麼
- description,這個工具是做什麼的
- inputSchema,這個工具需要傳入什麼
- outputSchema,這個工具會回傳什麼
特別值得一提,inputSchema、outputSchema 使用 zod 來定義型別。以右邊程式碼為例,該工具應該會回傳一個物件 { files: string[] }。
步驟 4: 實作 Tool 執行函數
server.registerTool(
'list_files',
{
title: '列出檔案',
description: '列出所有 Markdown 檔案',
inputSchema: {}, // 這裡不需要傳入任何參數
outputSchema: {
files: z.array(z.string())
}
},
async () => { /* @cat-caption → // [新增] 執行函數:工具被 AI 呼叫時執行,回傳結果直接送給 LLM 繼續思考 */
return { /* @cat-caption → // [新增] 回傳物件:標準 MCP 格式,content 是可讀文字,structuredContent 是結構化資料 */
content: [ // ← 必須是陣列 /* @cat-caption → // [新增] content 陣列:多模態支援(文字、圖片等),AI 「閱讀」此內容 */
{ /* @cat-caption → // [新增] 內容塊:type 定義類型,text 是純文字結果 */
type: 'text', // ← 內容類型 /* @cat-caption → // [新增] type 'text':標準文字輸出,AI 直接解析 */
text: '目前還沒有檔案' // ← 實際內容 /* @cat-caption → // [新增] text:工具結果的文字表示,模擬人類回報 */
} /* @cat-caption → // [新增] 單一內容塊結束:陣列允許多個塊,如文字+圖片 */
] /* @cat-caption → // [新增] content 結束:AI 主要依賴此閱讀結果 */
}; /* @cat-caption → // [新增] 回傳結束:函數 async 支援非同步操作,如讀檔、API 呼叫 */
} /* @cat-caption → // [新增] 函數註冊完成:現在工具完整,AI 可呼叫 */
);
再來, registerTool 的第三個參數傳入該工具的實際執行函數。一但工具被調用,該 function 會被執行,回傳數值便會直接送回給 LLM。
回傳數值必然會有 content ,他是一個陣列來告知 LLM 工具執行的結果。
步驟 5: 支援多模態內容(圖片範例)
// ... (前面的 registerTool 規格保持不變,僅修改執行函數)
async () => {
return {
content: [
{
type: "text",
text: "目前還沒有檔案",
},
{ // 簡單展示一下如果要回傳圖片該怎麼做 /* @cat-caption → // [新增] 圖片內容塊:content 支援多模態,擴展工具豐富度(如顯示檔案預覽) */
type: "image", /* @cat-caption → // [新增] type 'image':圖片類型,AI 可視覺化顯示 */
data: "base64 編碼的圖片", /* @cat-caption → // [新增] data:Base64 編碼圖片資料,直接內嵌無需外部 URL */
mimeType: "image/png", /* @cat-caption → // [新增] mimeType:指定格式(如 PNG),確保 AI 正確渲染 */
}, /* @cat-caption → // [新增] 多模態好處:文字+圖片讓 AI 更全面理解結果,提升互動體驗 */
],
};
}
回傳數值中的 content,不只可以回傳文字、還可以加入圖片、音訊、檔案等內容。
(右側程式碼僅為舉例)
步驟 6: 新增 structuredContent
async () => {
const output = { files: [] }; // ← 先用空陣列 /* @cat-caption → // [新增] output 物件:對應 outputSchema,結構化資料供 AI 程式化解析 */
return {
content: [
{
type: "text",
text: JSON.stringify(output, null, 2), /* @cat-caption → // [新增] JSON.stringify:將結構化資料轉文字,讓 AI 「閱讀」易懂版本 */
}
],
structuredContent: output // 同時提供結構化資料 /* @cat-caption → // [新增] structuredContent:純 JSON 物件,AI 可精準解析(如提取 files 陣列),而不依賴文字 */
};
}
回傳數值除了 content,還有 structuredContent。
content:給 AI「閱讀」的文字內容
structuredContent:給程式「解析」的結構化資料
通常來說,structuredContent 跟 content 的內容是一摩一樣的,只是 content 的內容可能透過 JSON.stringify 轉成純文字,讓 LLM 可以直接閱讀。
步驟 7: 設定 MCP HTTP Endpoint
import { StreamableHTTPServerTransport } from '@modelcontextprotocol/sdk/server/streamableHttp.js'; /* @cat-caption → // [新增] 匯入 Transport:HTTP 傳輸層,處理 MCP JSON-RPC 協議的串流請求 */
// ... (前面的 server 與工具註冊保持不變)
// MCP endpoint /* @cat-caption → // [新增] /mcp POST endpoint:MCP 標準入口,AI 客戶端發送請求至此 */
app.post('/mcp', async (req, res) => { /* @cat-caption → // [新增] POST 處理器:接收 req.body(JSON-RPC),回應工具呼叫或連接 */
try { /* @cat-caption → // [新增] try-catch:確保錯誤不崩伺服器,回傳標準 MCP 錯誤格式 */
const transport = new StreamableHTTPServerTransport({ /* @cat-caption → // [新增] StreamableHTTP Transport:支援串流,適合長連接與即時互動 */
sessionIdGenerator: undefined, /* @cat-caption → // [新增] sessionId:預設自動生成,用於多會話區分 */
enableJsonResponse: true /* @cat-caption → // [新增] JSON 回應:簡化除錯與相容,否則用 SSE 串流 */
}); /* @cat-caption → // [新增] Transport 初始化:橋接 Express 與 MCP 協議 */
/* @cat-caption → // [新增] 關閉處理:res 關閉時清理 transport,避免資源洩漏 */
res.on('close', () => transport.close()); /* @cat-caption → // [新增] 註冊 close 事件:確保連線終止時正確清理 */
/* @cat-caption → // [新增] 連接 server:將 transport 綁定到 McpServer,啟用工具路由 */
await server.connect(transport); /* @cat-caption → // [新增] handleRequest:處理單一請求,自動路由到工具或初始化 */
await transport.handleRequest(req, res, req.body); /* @cat-caption → // [新增] 請求委派:SDK 自動解析 JSON-RPC,呼叫對應工具 */
} catch (error) { /* @cat-caption → // [新增] 錯誤處理:記錄 log 並回傳標準 JSON-RPC 錯誤 */
console.error('MCP 請求錯誤:', error); /* @cat-caption → // [新增] 避免 headers 已送:防止重複回應 */
if (!res.headersSent) { /* @cat-caption → // [新增] 標準錯誤格式:code -32603 是內部錯誤,id 對應請求 */
res.status(500).json({ /* @cat-caption → // [新增] JSON-RPC 錯誤回應:確保 AI 客戶端正確解析 */
jsonrpc: '2.0', /* @cat-caption → // [新增] 協議版本 */
error: { code: -32603, message: 'Internal server error' }, /* @cat-caption → // [新增] 錯誤細節 */
id: null /* @cat-caption → // [新增] 請求 ID:null 表示非特定請求 */
}); /* @cat-caption → // [新增] 錯誤回應結束:提升伺服器穩定性 */
} /* @cat-caption → // [新增] catch 結束 */
} /* @cat-caption → // [新增] POST 結束:現在 MCP 對外可用 */
}); /* @cat-caption → // [新增] endpoint 註冊完成 */
// ... (health 與 listen 保持不變,更新 console log)
console.log(`📍 MCP endpoint:http://localhost:${port}/mcp`);
現在,將整個 MCP 伺服器透過 Express 對外開放,讓 AI 客戶端可以連接。
第三步,測試看看 MCP 伺服器有沒有建立成功
💻 MCP Inspector 測試工具
🎯 學習目標:使用官方 Inspector 驗證連接與工具列表確認 endpoint 正確配置
步驟 1: 啟動 MCP Inspector
npx @modelcontextprotocol/inspector http://localhost:8080/mcp
這邊可以在終端機中直接打入一串指令,開啟 mcp 測試工具。
圖: 終端機指令(寬度 600px,右下)
步驟 2: 開啟測試網站
輸入完成後,他會開啟一個網站。
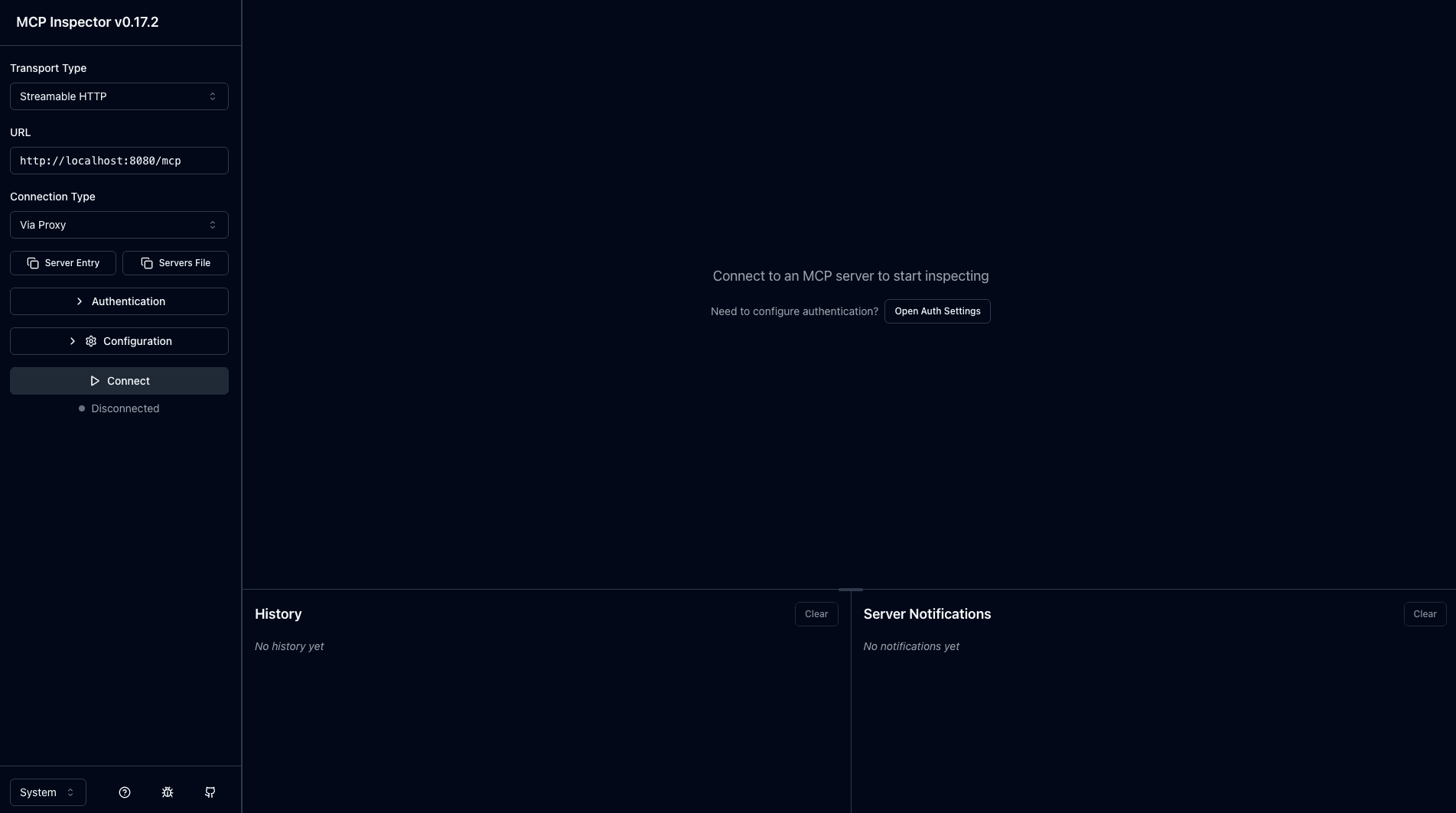
圖: MCP Inspector 介面(全寬)
步驟 3: 設定 Transport Type
確保 Transport Type 是 Streamable HTTP。
圖: 選擇 Streamable HTTP(全寬)
步驟 4: 輸入 MCP URL
確保 URL 是 http://localhost:8080/mcp 。
圖: 輸入正確 URL(全寬)
步驟 5: 按下 Connect
按下 Connect。
圖: 點擊連接(全寬)
步驟 6: 確認連接成功
你應該可以看到連接成功,你可以點擊中間的 List Tools。
圖: 連接狀態(全寬)
步驟 7: 查看工具列表
應該可以看到我們創建的工具「list files」。
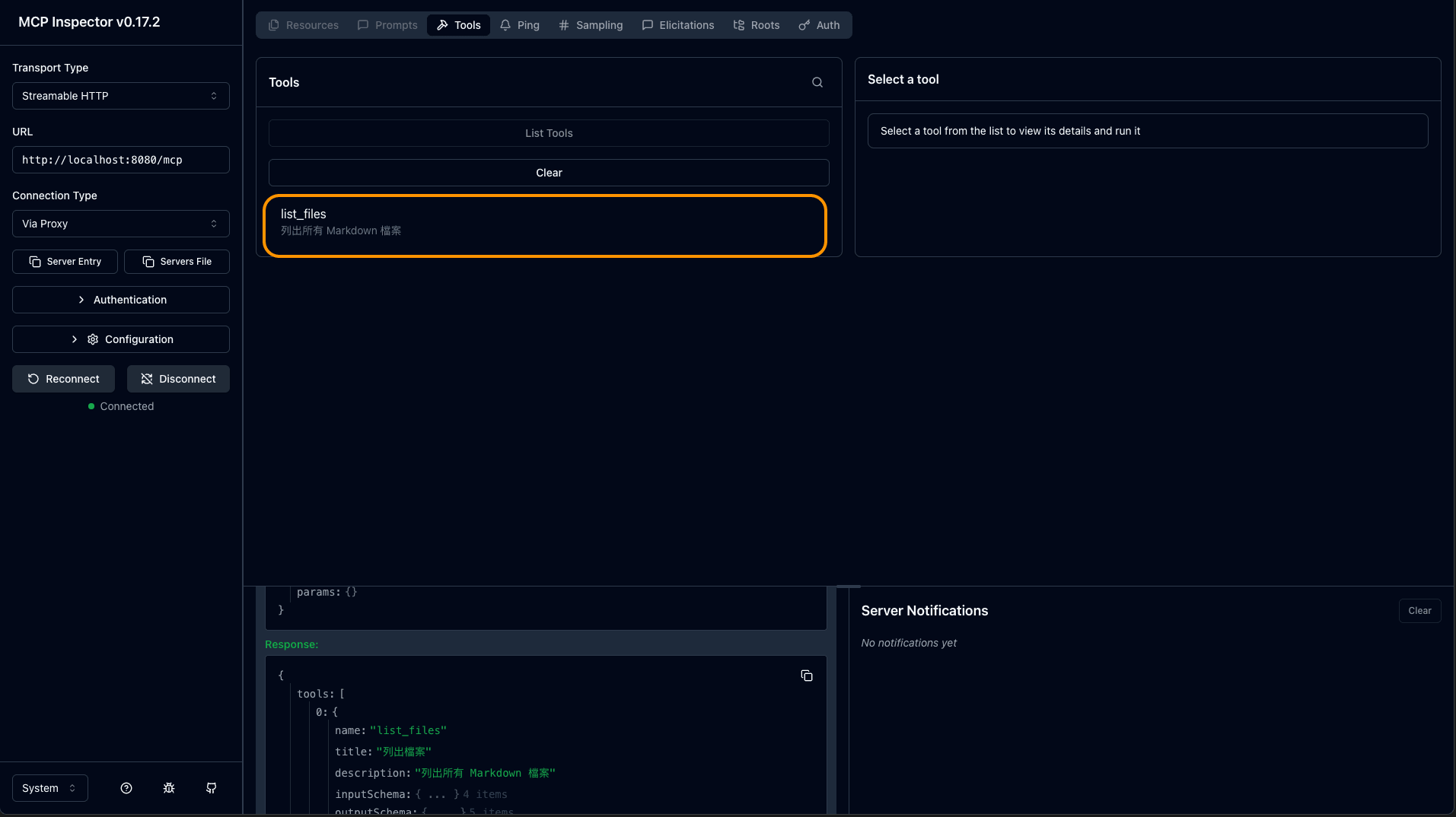
圖: list_files 工具顯示(全寬)
第四步,實作檔案系統讀取
我們來把 list_files 的功能給實際做出來。由於本教學的重點是 MCP,我會用很快的速度帶過去,就不特別提細節了。
💻 實作檔案讀取功能
🎯 學習目標:使用 Node.js fs 讀取 notes 資料夾過濾 Markdown 檔案並回傳列表加入錯誤處理
步驟 1: 建立 notes 資料夾
為了方便測試,我建議在專案資料夾中建立一個 notes 資料夾。我們的 mcp 工具會把該資料夾當作我們的筆記目錄。
圖: 建立 notes 資料夾(全寬)
步驟 2: 修改 list_files 實作讀取邏輯
import fs from 'fs/promises'; /* @cat-caption → // [新增] fs/promises:非同步檔案系統 API,讀取目錄高效且不阻塞事件迴圈 */
import path from 'path'; /* @cat-caption → // [新增] path:處理檔案路徑跨平台相容,避免 Windows/Linux 路徑差異 */
// 筆記目錄 /* @cat-caption → // [新增] NOTES_DIR:固定根目錄,集中管理筆記位置,未來易擴展子資料夾 */
const NOTES_DIR = './notes'; /* @cat-caption → // [新增] 相對路徑:相對於專案根目錄,確保部署時一致 */
server.registerTool(
'list_files',
{
// ... (規格保持不變)
},
async () => {
try { /* @cat-caption → // [新增] try-catch:捕捉讀取錯誤(如資料夾不存在),回傳使用者友善訊息 */
const entries = await fs.readdir(NOTES_DIR, { withFileTypes: true }); /* @cat-caption → // [新增] readdir:讀取目錄所有項目,withFileTypes 獲取檔案類型資訊 */
const files = entries /* @cat-caption → // [新增] filter:僅保留檔案(非目錄)且副檔名 .md,聚焦 Markdown 筆記 */
.filter(entry => entry.isFile() && entry.name.endsWith('.md')) /* @cat-caption → // [新增] map:提取純檔名,簡化回傳給 AI */
.map(entry => entry.name); /* @cat-caption → // [新增] 過濾與映射完成:生成乾淨的檔案列表 */
const output = { files }; /* @cat-caption → // [新增] output:符合 outputSchema,結構化結果 */
return { /* @cat-caption → // [新增] 成功回傳:content 文字版,structuredContent 結構版 */
content: [{ type: 'text', text: JSON.stringify(output, null, 2) }], /* @cat-caption → // [新增] 美化 JSON:null,2 縮排,讓 AI 易讀 */
structuredContent: output /* @cat-caption → // [新增] 雙重回傳:文字供閱讀,結構供解析 */
}; /* @cat-caption → // [新增] 回傳結束 */
} catch (error) { /* @cat-caption → // [新增] 錯誤分支:轉換 Error 物件,避免型別錯誤 */
return { /* @cat-caption → // [新增] 錯誤標記:isError 讓 AI 知道失敗,專注錯誤處理 */
content: [{ type: 'text', text: `錯誤:${(error as Error).message}` }], /* @cat-caption → // [新增] 友善錯誤訊息:包含具體原因,如「無此資料夾」 */
isError: true /* @cat-caption → // [新增] isError:MCP 標準旗標,AI 會調整後續行為 */
}; /* @cat-caption → // [新增] 錯誤回傳 */
} /* @cat-caption → // [新增] 工具函數結束:現在真正讀取檔案 */
}
);
// ... (MCP endpoint 與 console log 保持不變,新增筆記目錄 log)
console.log(`📂 筆記目錄:${NOTES_DIR}`);
我這邊使用 fs.readdir() 讀取目錄,過濾出 .md 檔案,然後回傳給 LLM。
步驟 3: 新增測試檔案
在 /notes 資料夾中,放一些檔案方便測試。
圖: notes 資料夾內檔案(全寬)
步驟 4: 測試檔案列表
回到剛剛提到的 mcp 測試網站(來自 第三步,測試看看 MCP 伺服器有沒有建立成功)。
你可以執行看看 list_files 工具,應該可以看到所有檔案。
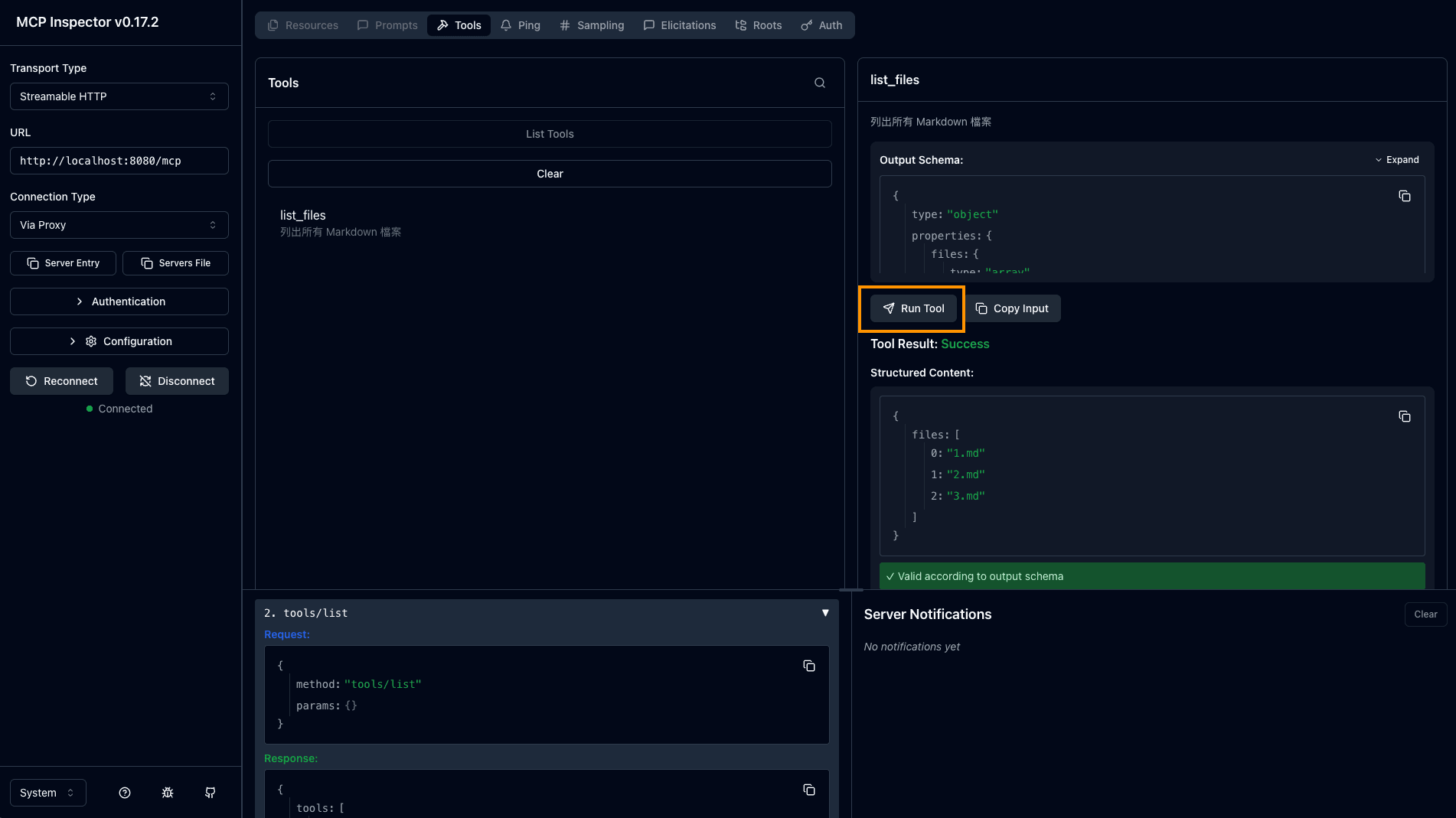
圖: Inspector 執行結果顯示檔案列表(全寬)
第五步,接到 ChatGPT 或者 Claude 的前置作業:Ngrok
恭喜你!現在我們的 MCP Server 已經跑起來了,但有個問題:ChatGPT 在雲端,怎麼連到你電腦上的 localhost:3000?
(不知道為什麼讓我想到這個工程師老梗
圖: 工程師 localhost 笑話(高度 442px,寬度 474px)
外部的電腦是沒辦法連線到我 localhost 的網站,該怎麼辦呢?
難道只能部署到雲端嗎?
這邊推薦給大家一個超讚的免費服務 ngrok
他可以開了一個「臨時的公開網址」,外面的人可以把信件寄到這公開網址,而 ngrok 會把收到的信再轉交給你家裡的電腦。
這樣就可以讓 ChatGPT、Claude 直接連到你的電腦的 MCP 伺服器了。
💻 使用 ngrok 暴露本地服務
🎯 學習目標:安裝並配置 ngrok生成公開 HTTPS URL 轉發 localhost:8080
步驟 1: 註冊並登入 ngrok
首先,打開 ngrok 的服務 https://ngrok.com/ 並且登入。
圖: ngrok 官網登入(全寬)
步驟 2: 安裝 ngrok(以 macOS 為例)
造著他的方式安裝他,以 macos homebrew 為例。
打開終端機
- 先輸入
brew install ngrok安裝整個程式碼 - 然後輸入
ngrok config add-authtoken XXX登入你的帳號
這樣就完成安裝了。
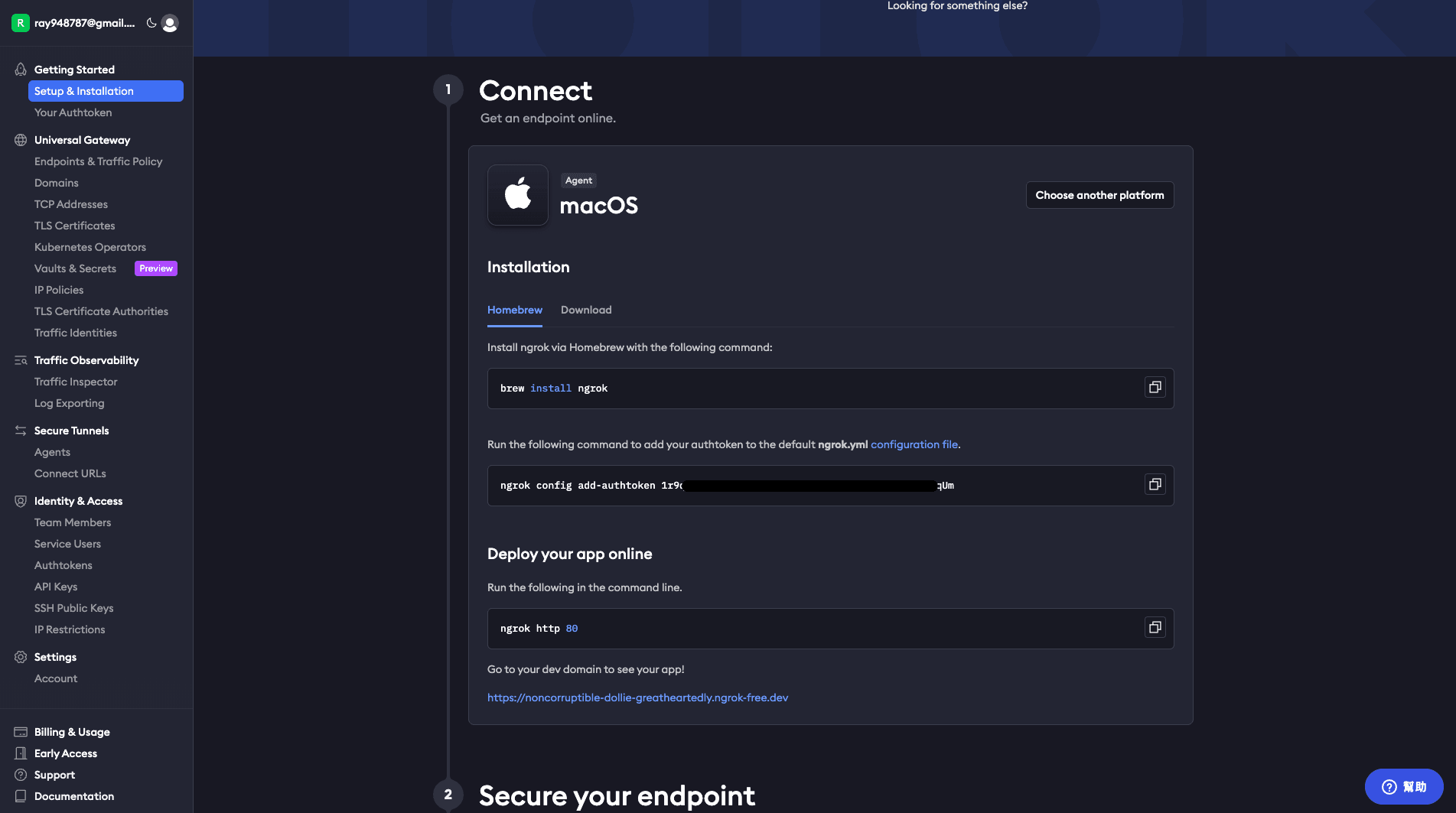
圖: Homebrew 安裝與 auth(全寬)
步驟 3: 暴露 8080 埠
ngrok http 8080
接著重點來了,我們要將本地端的 HTTP 服務,8080 Port 給公開到網路上,請輸入右邊這個指令到終端機中。

圖: ngrok http 命令(寬度 300px,右上)
步驟 4: 複製公開 URL
Ok! 他接下來會生成一個網址,恭喜你,這就是你 MCP 的網址,把它複製下來。終端機不要關掉,一但關掉這個網址會失效。
任何針對這個網址的請求,都會直接送到你電腦中的 localhost:8080。
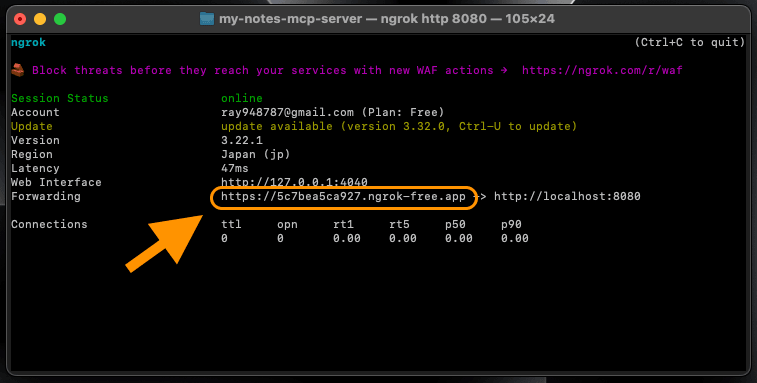
圖: 生成的公開 URL(全寬)
第六步之一,接到 ChatGPT
請注意!ChatGPT 的 MCP 功能需要訂閱(每個月 20 美金方案以上)才可以使用
💻 連接 ChatGPT
🎯 學習目標:啟用 ChatGPT 開發者模式新增自訂 MCP Connector
步驟 1: 開啟 ChatGPT 設定
打開你的 ChatGPT,並點擊左下角。
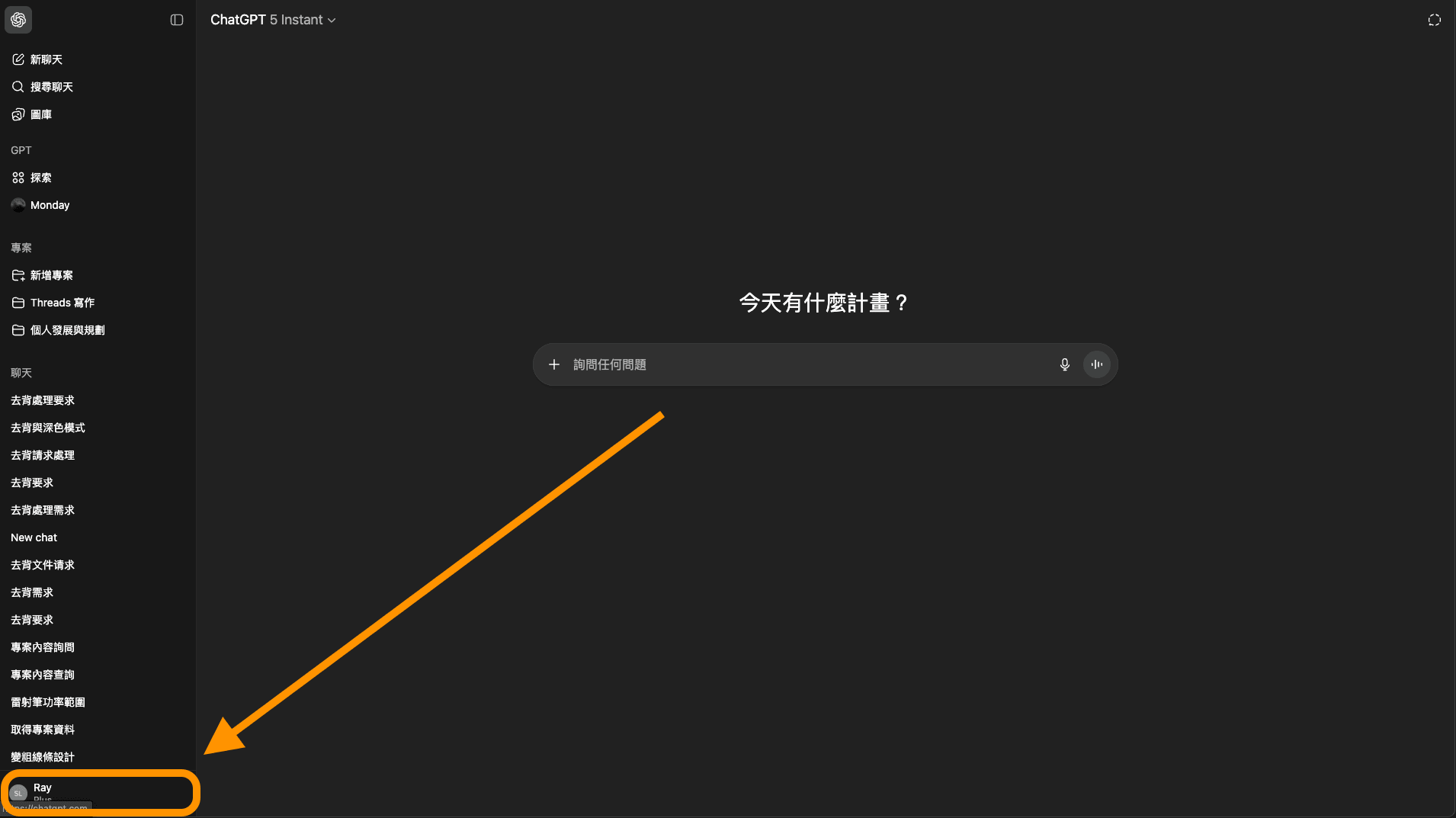
圖: 左下角設定(全寬)
步驟 2: 進入設定
選擇「設定」。
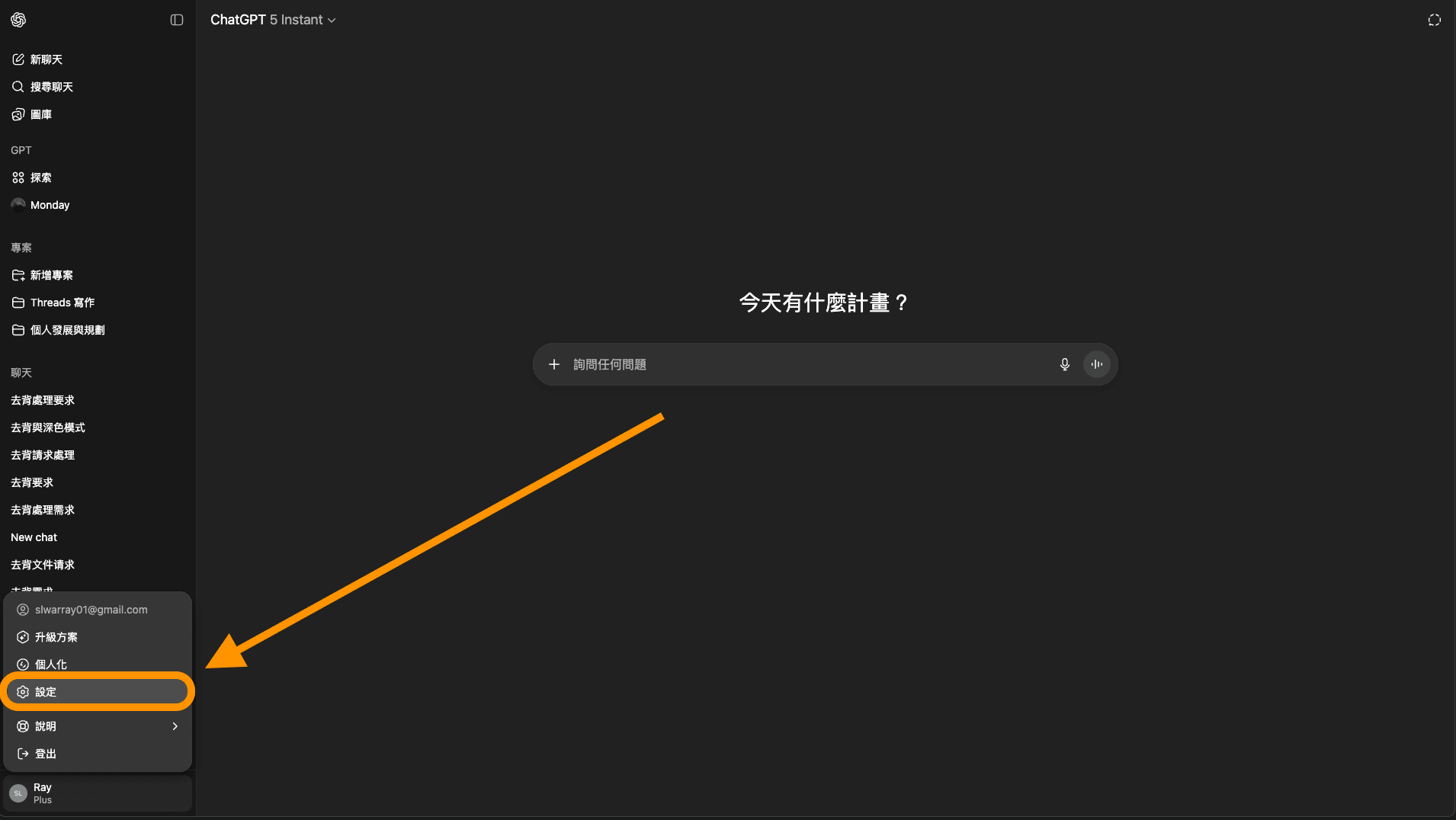
圖: 選擇設定(全寬)
步驟 3: 應用程式和連接器
選擇「應用程式和連接器」。
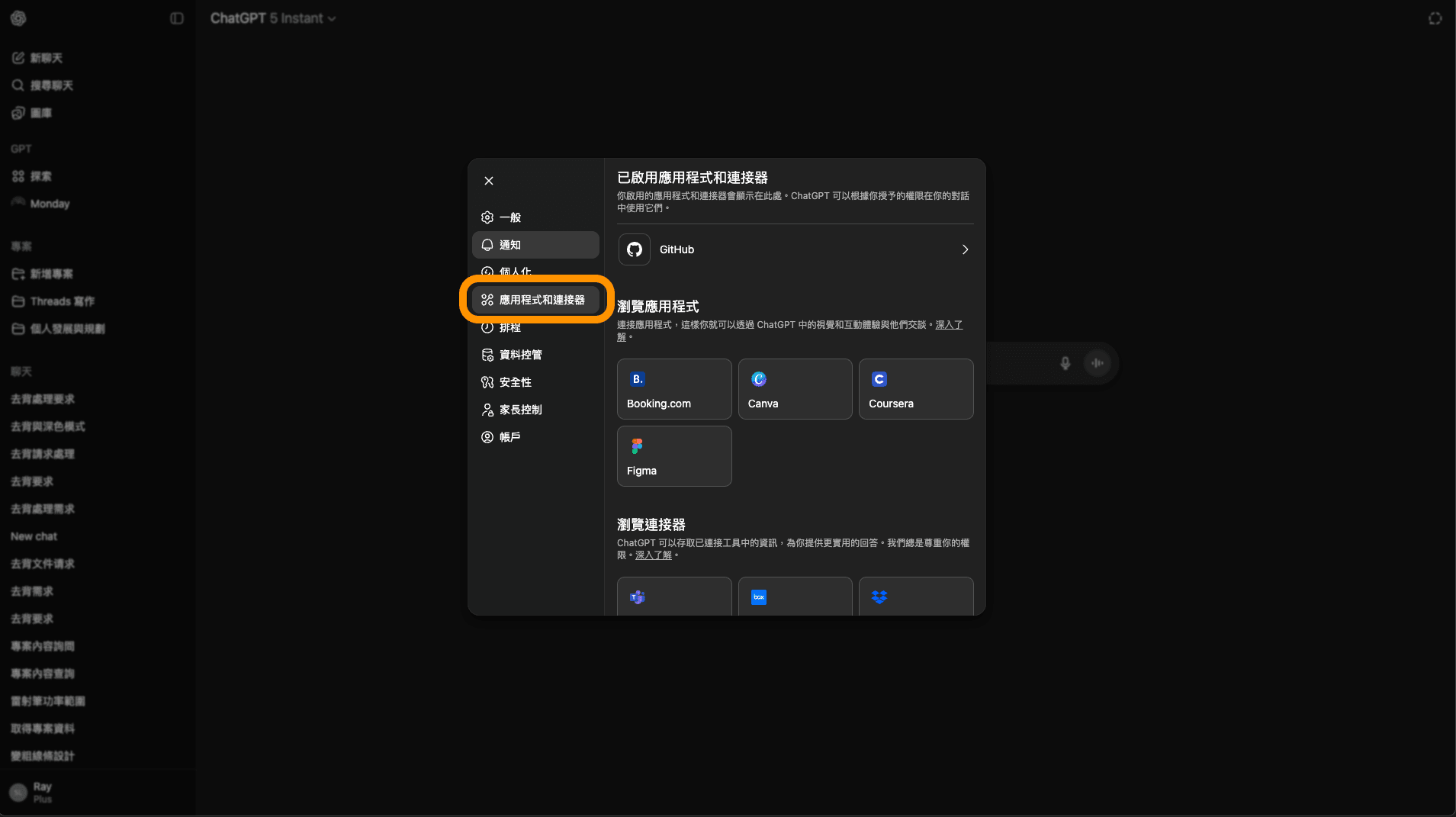
圖: 應用程式和連接器(全寬)
步驟 4: 進階設定
滑到最底下,選擇「進階設定」。
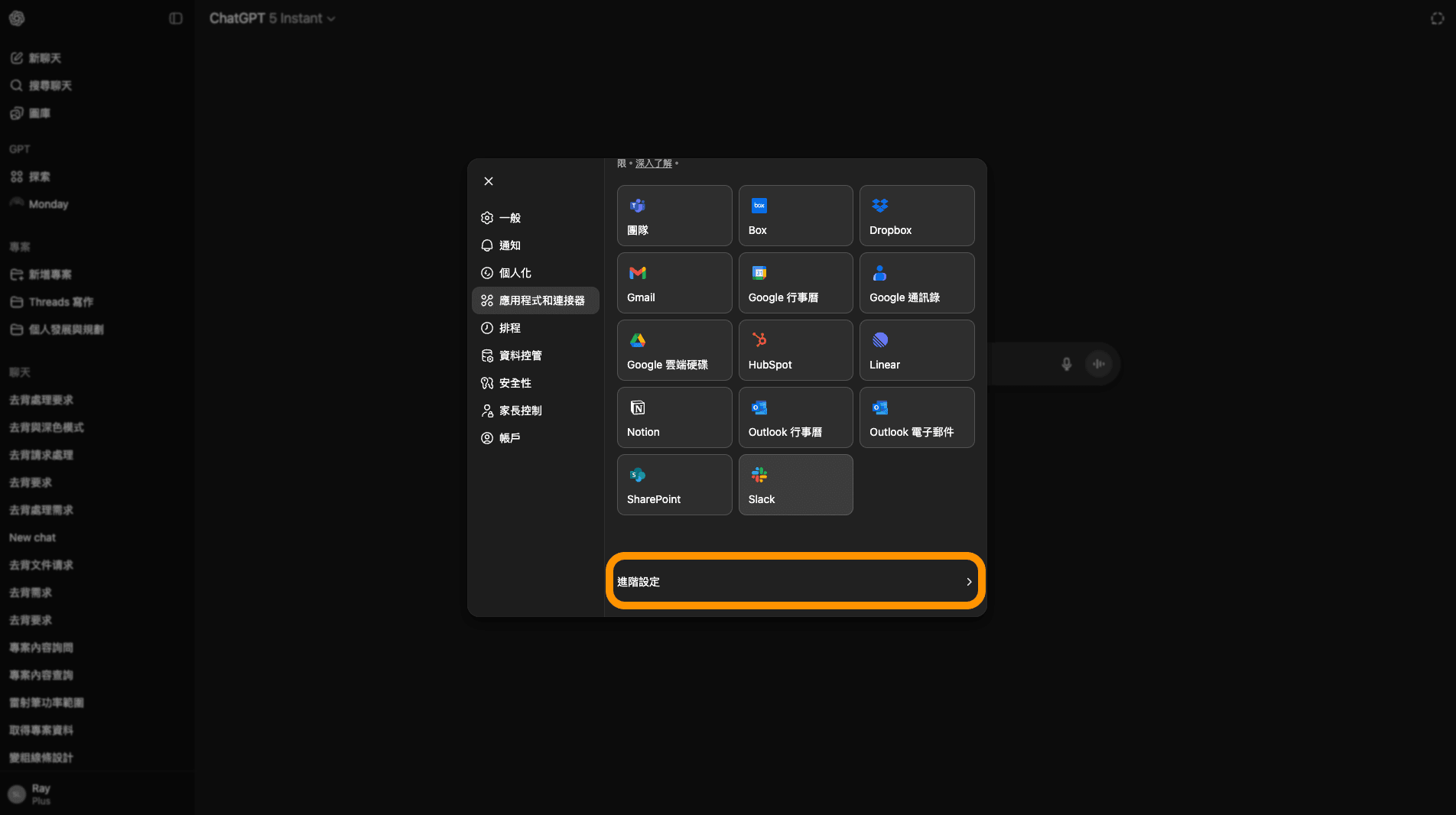
圖: 進階設定(全寬)
步驟 5: 開啟開發者模式
開啟「開發者模式」,並回到上一步。
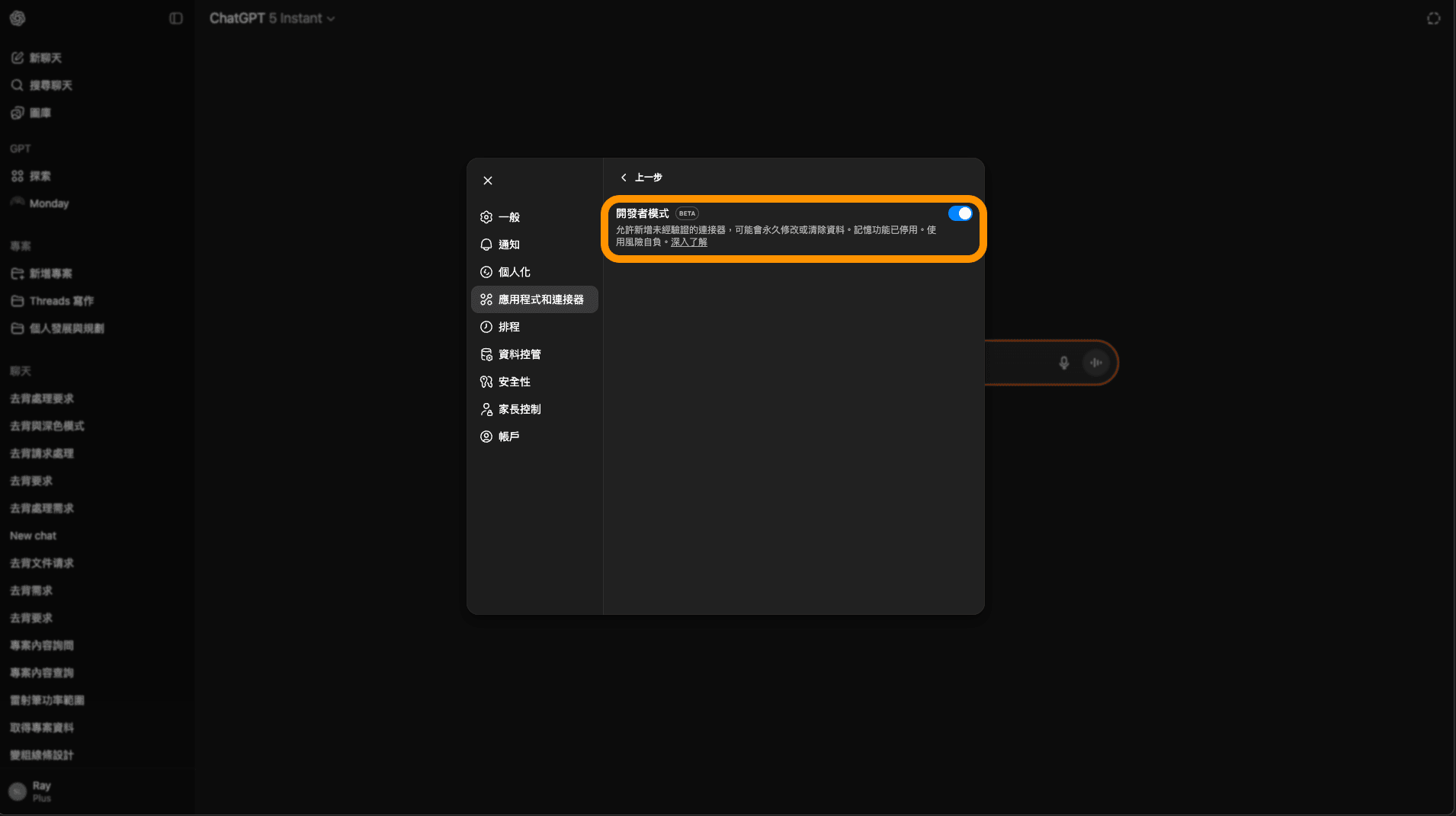
圖: 啟用開發者模式(全寬)
步驟 6: 建立 Connector
點擊「建立」。
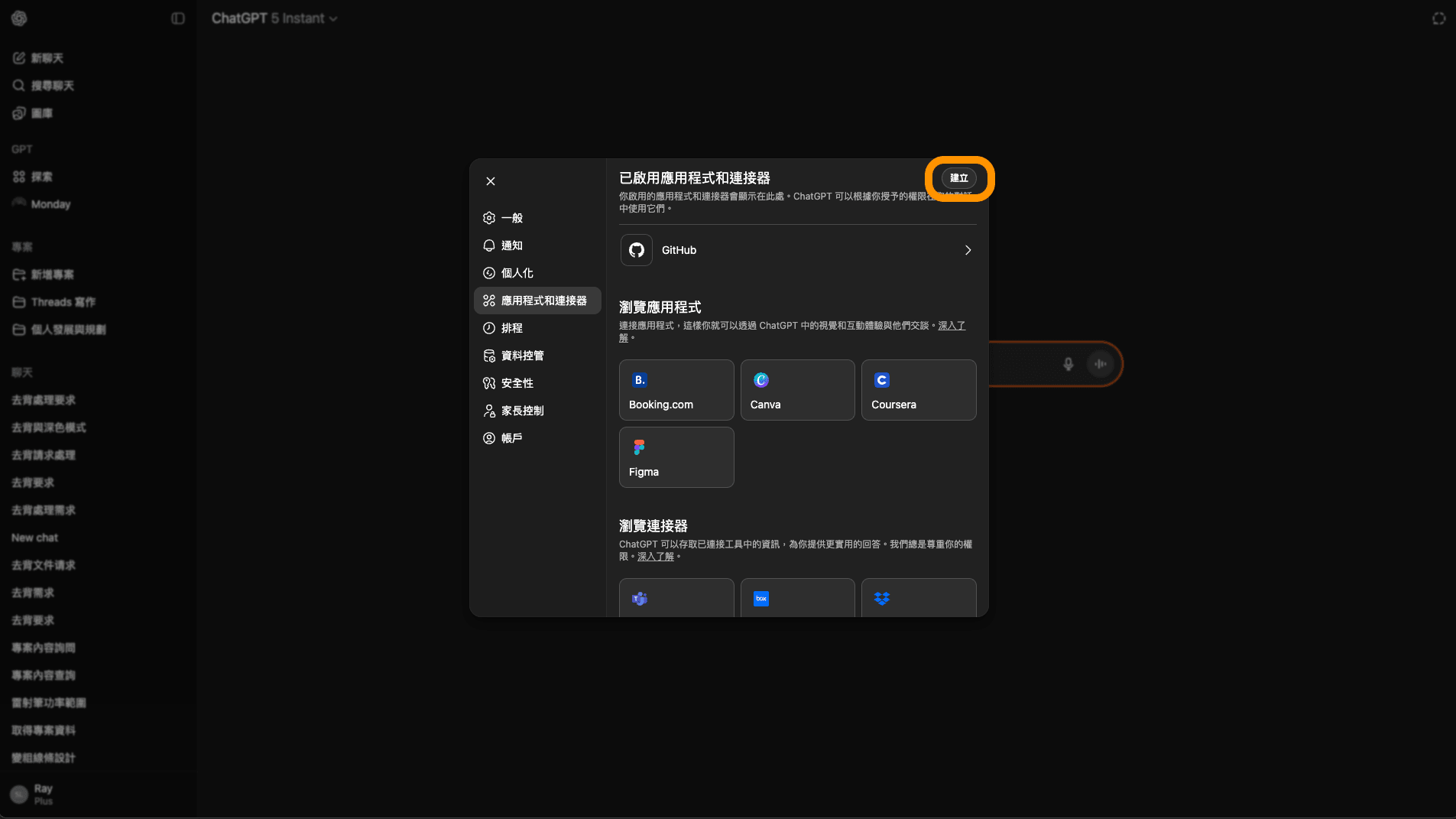
圖: 建立新連接器(全寬)
步驟 7: 輸入名稱
輸入這個 MCP 伺服器的名稱。
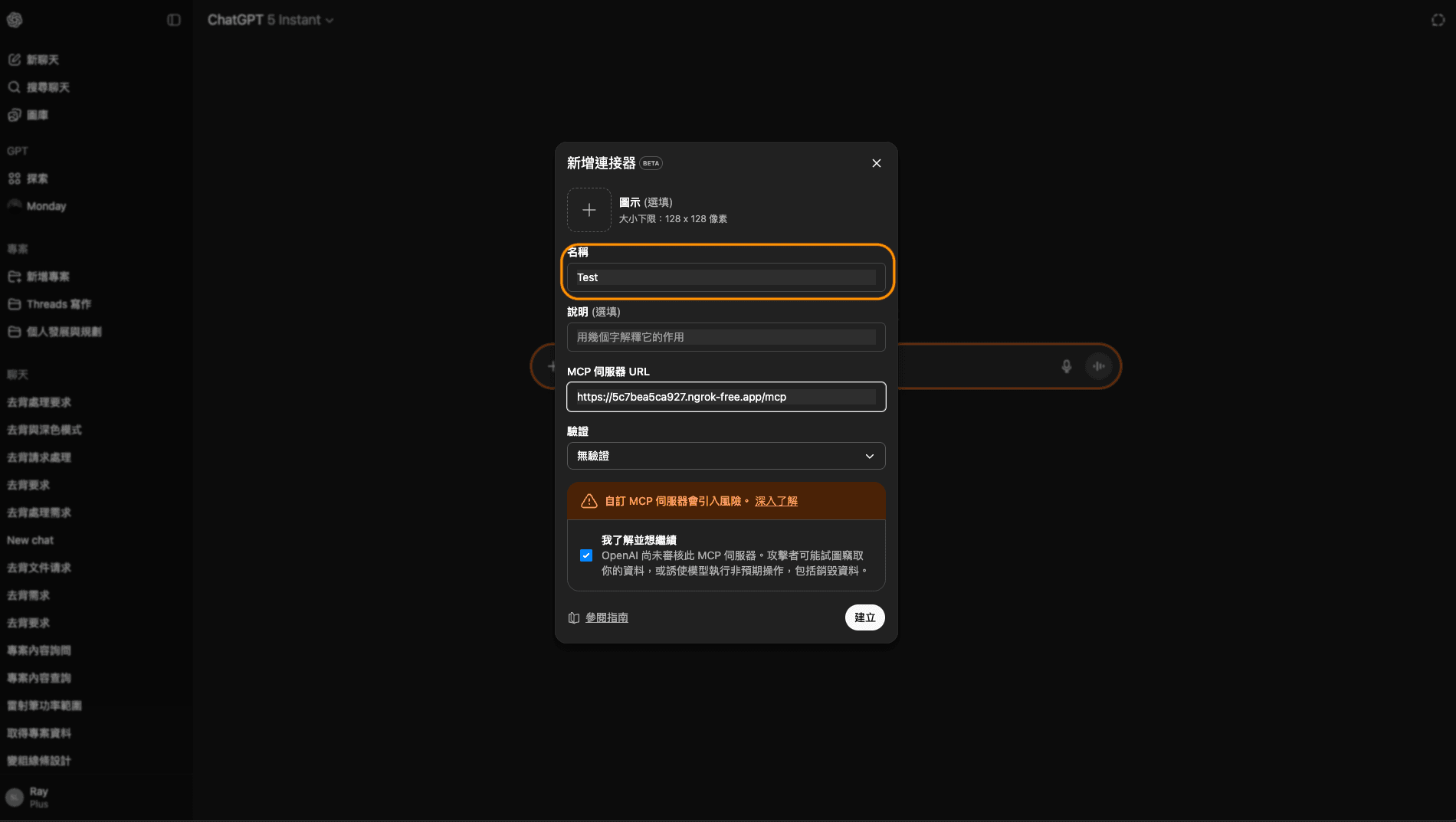
圖: 連接器名稱(全寬)
步驟 8: 輸入 ngrok URL
重點來了!貼上 ngrok 的網址,記得!!最後要加上 /mcp。
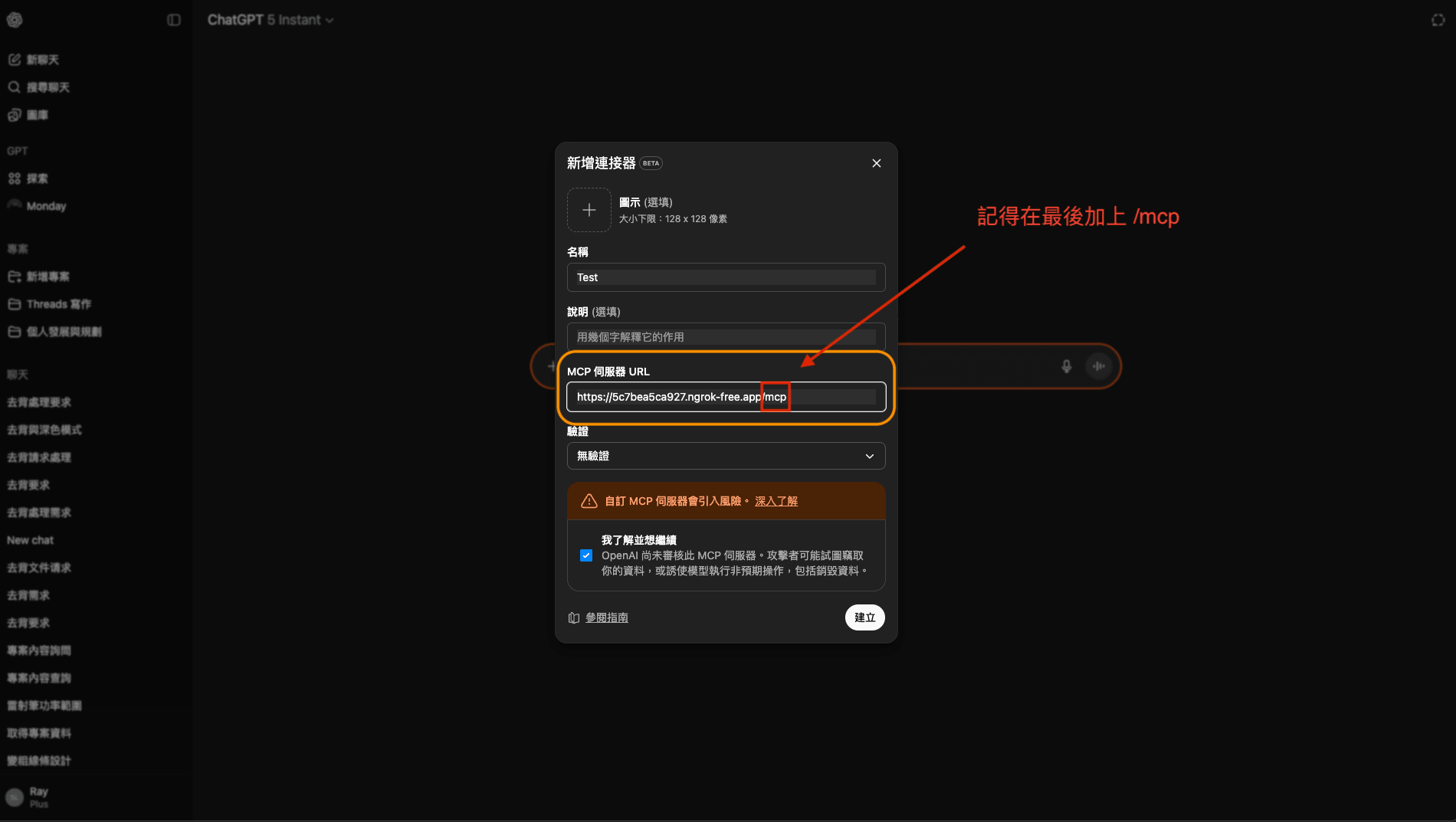
圖: MCP URL(全寬)
步驟 9: 設定無驗證
把「驗證」改成「無驗證」。
圖: 驗證設定(全寬)
步驟 10: 確認並建立
點擊「我了解並繼續」,最後選擇建立。
圖: 繼續與建立(全寬)
步驟 11: 連接成功
順利的話,就可以看到我們的 MCP 服務。
圖: MCP 服務顯示(全寬)
步驟 12: 開始聊天測試
到這邊就可以直接跟 ChatGPT 聊天,順利的話,恭喜成功串接 MCP 到 ChatGPT 上頭!
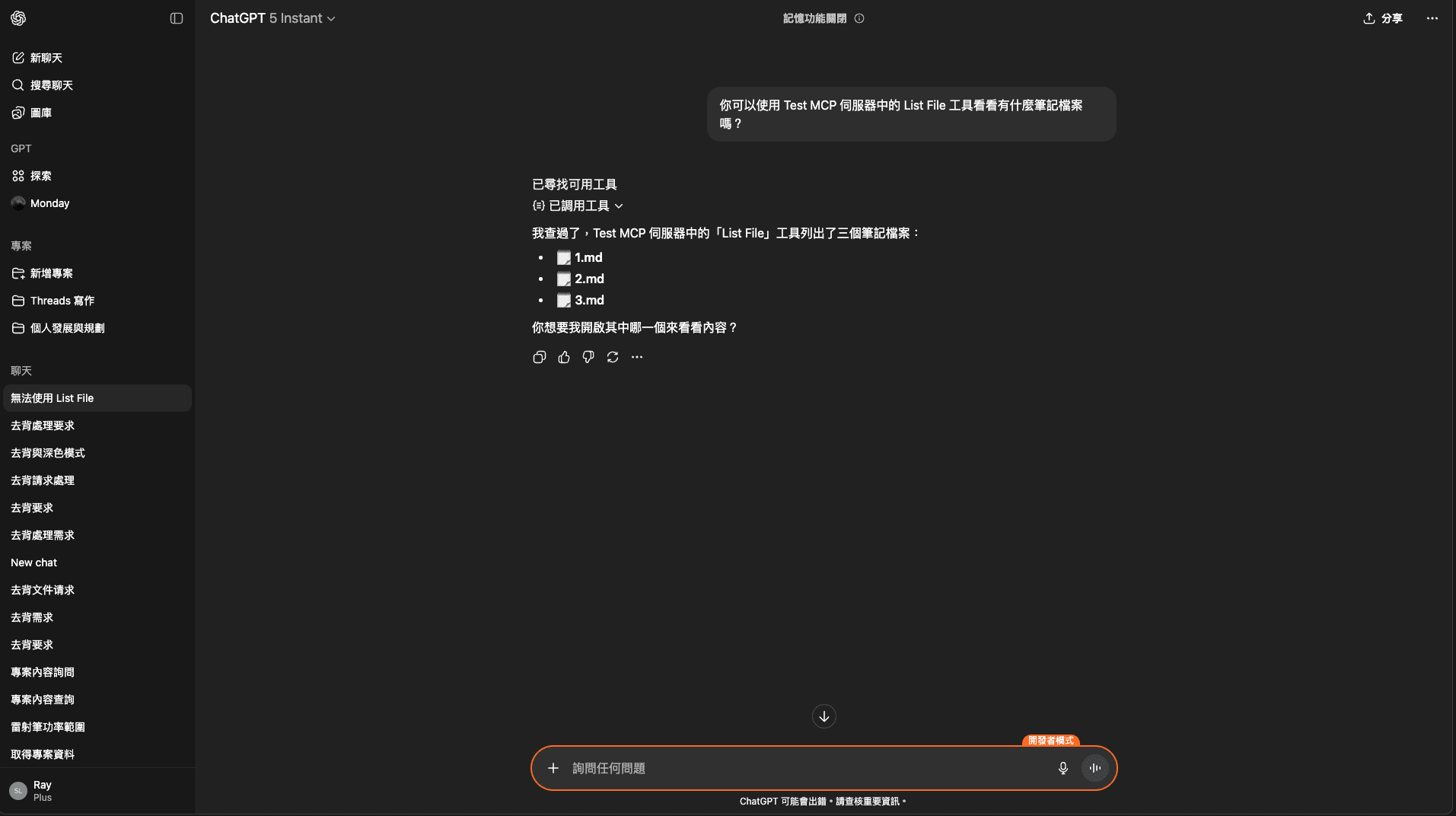
圖: ChatGPT 聊天中使用 MCP(全寬)
第六步之二,接到 Claude
請注意!Claude 的 MCP 功能需要訂閱(每個月 20 美金方案以上)才可以使用
Claude 的邏輯跟 ChatGPT 很像,
💻 連接 Claude
🎯 學習目標:使用 Claude Connectors 新增自訂 MCP
步驟 1: 開啟 Claude 設定
打開你的 Claude,並點擊左下角。
圖: 左下角設定(全寬)
步驟 2: Settings
選擇「Settings」。
圖: Settings 選單(全寬)
步驟 3: Connectors
選擇「Connectors」並點擊「Add custom connector」。
圖: Connectors 頁面(全寬)
步驟 4: 輸入名稱
輸入這個 MCP 伺服器的名稱。
圖: 連接器名稱(全寬)
步驟 5: 輸入 ngrok URL
重點來了!貼上 ngrok 的網址,記得!!最後要加上 /mcp,最後按下 Add。
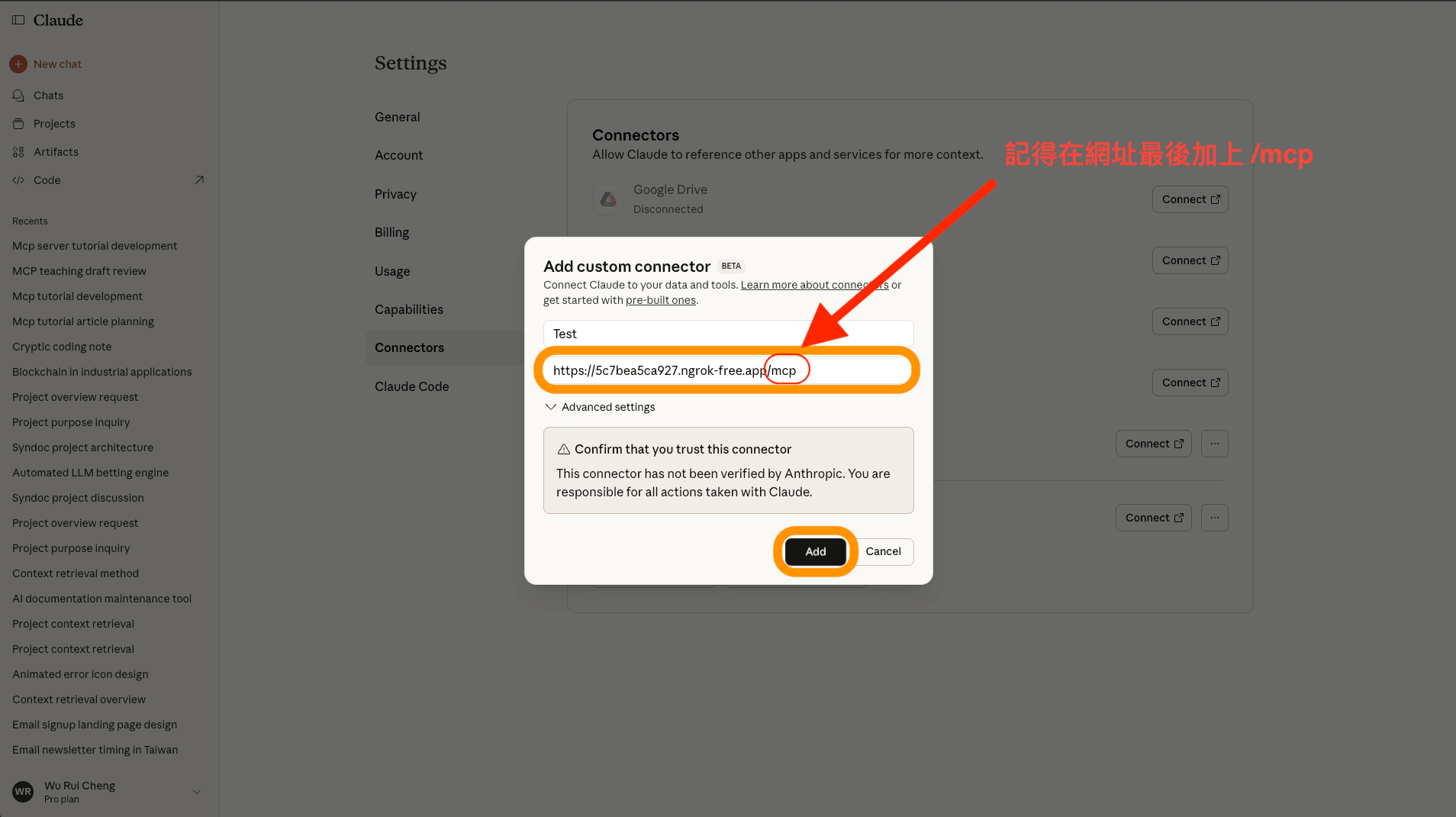
圖: MCP URL(全寬)
步驟 6: 連接成功
順利的話,就可以看到我們的 MCP 服務。
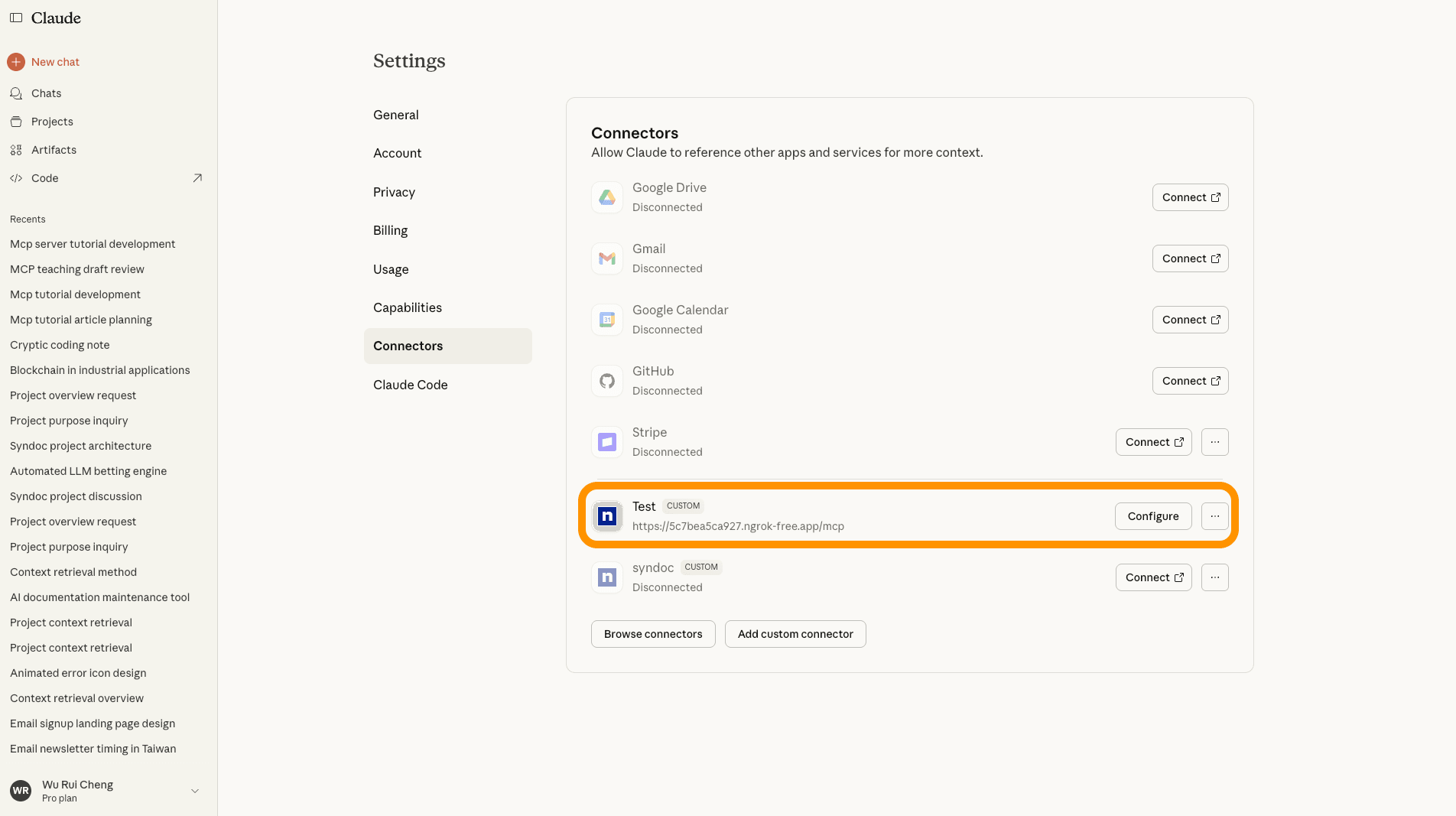
圖: 連接列表(全寬)
步驟 7: 開始聊天測試
到這邊就可以直接跟 ChatGPT 聊天,順利的話,恭喜成功串接 MCP 到 Claude 上頭!
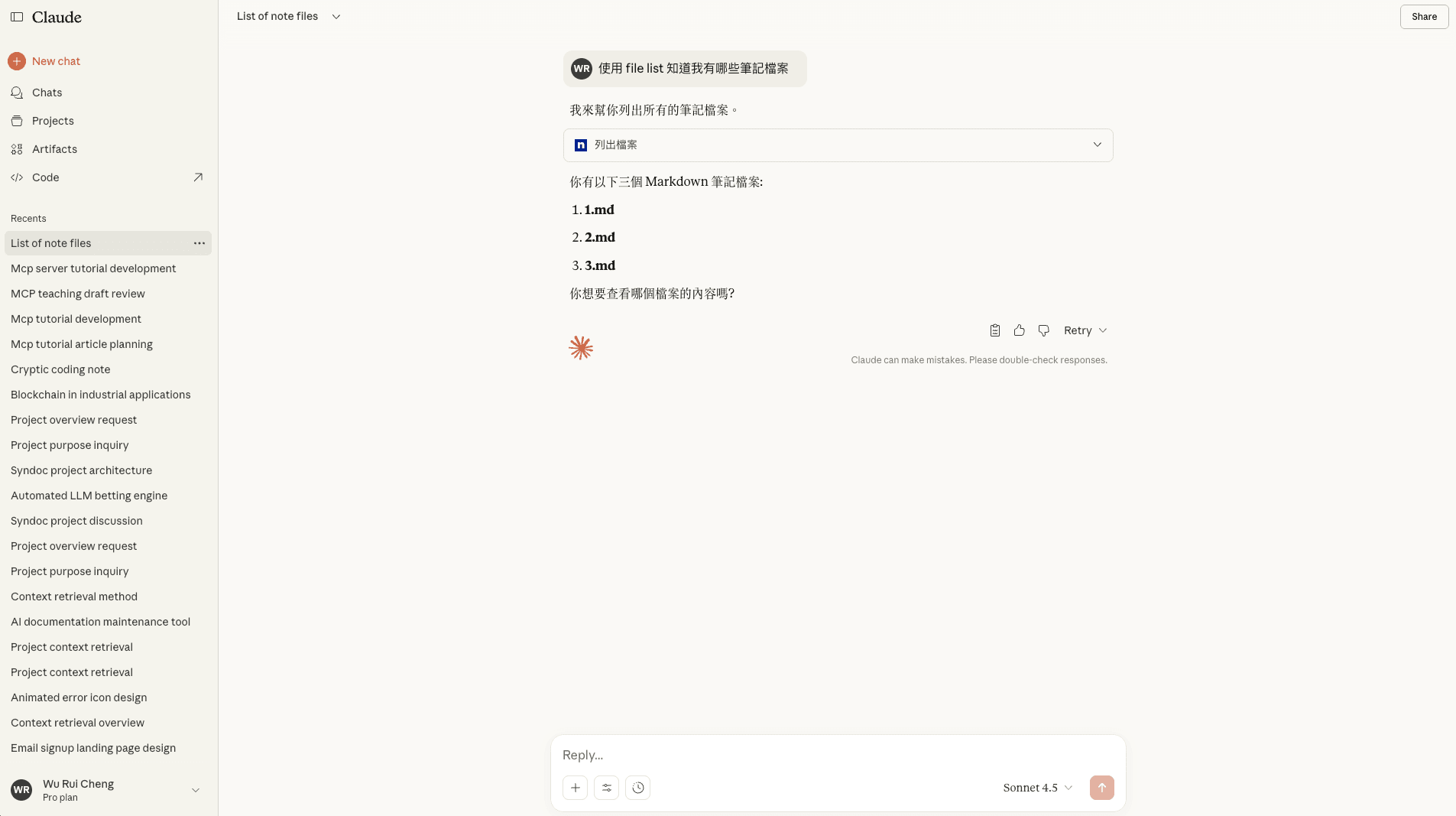
圖: Claude 聊天中使用 MCP(全寬)
你已經學會了
理解 MCP 解決的核心問題
- 為什麼 REST API 不夠
- AI 需要自動發現和使用工具的能力
- 標準化協定的重要性
掌握 Tools 的設計哲學
- Model-Controlled:AI 決定何時使用
- Action-Oriented:執行動作、產生結果
- Schema-Defined:明確的輸入輸出規格
建立第一個實用的 MCP Server
- 完整的 list_notes tool 實作
- 錯誤處理和友善的訊息
整合到真實的 AI 應用
- 使用 ngrok 建立公開 URL
- 連接到 ChatGPT、Claude
- 實際對話測試
但這只是開始⋯⋯
你現在擁有了一個可運作的 MCP Server,但它還很基礎。
下一篇則會更深入 MCP 的精髓,講解 Resources 和 Prompts 的功能
我會分享很多開發 MCP 必定會遇到大問題以及解法,好比身份驗證、很多必須避開的坑
在 AI 時代,重點不是寫多少 code,而是理解問題、設計方案、驗證效果。Code 可以讓 AI 幫你寫,思考無法委託。
準備好了嗎?讓我們在下篇繼續深入 MCP 的世界!